[论文解读] Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Video-ChatGPT 将视频适应的 CLIP 编码器与基于 Vicuna 的大型语言模型相结合,在 100k video-instruction 对对上进行训练,并引入一个定量的视频对话评估框架,以实现详细的开放式视频对话。
Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the under-explored field of \emph{video-based conversation} by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with an LLM. The resulting model is capable of understanding and generating detailed conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantitative evaluation framework for video-based dialogue models to objectively analyze the strengths and weaknesses of video-based dialogue models. Code: https://github.com/mbzuai-oryx/Video-ChatGPT.
研究动机与目标
- 激发关于视频的开放式、连贯对话,超越传统的问答。
- 通过为视频定制的视觉-语言模型实现时空理解。
- 提供一个可扩展的高质量视频指令数据生成框架。
- 提供一个基准框架,用于定量评估基于视频的对话能力。
提出的方法
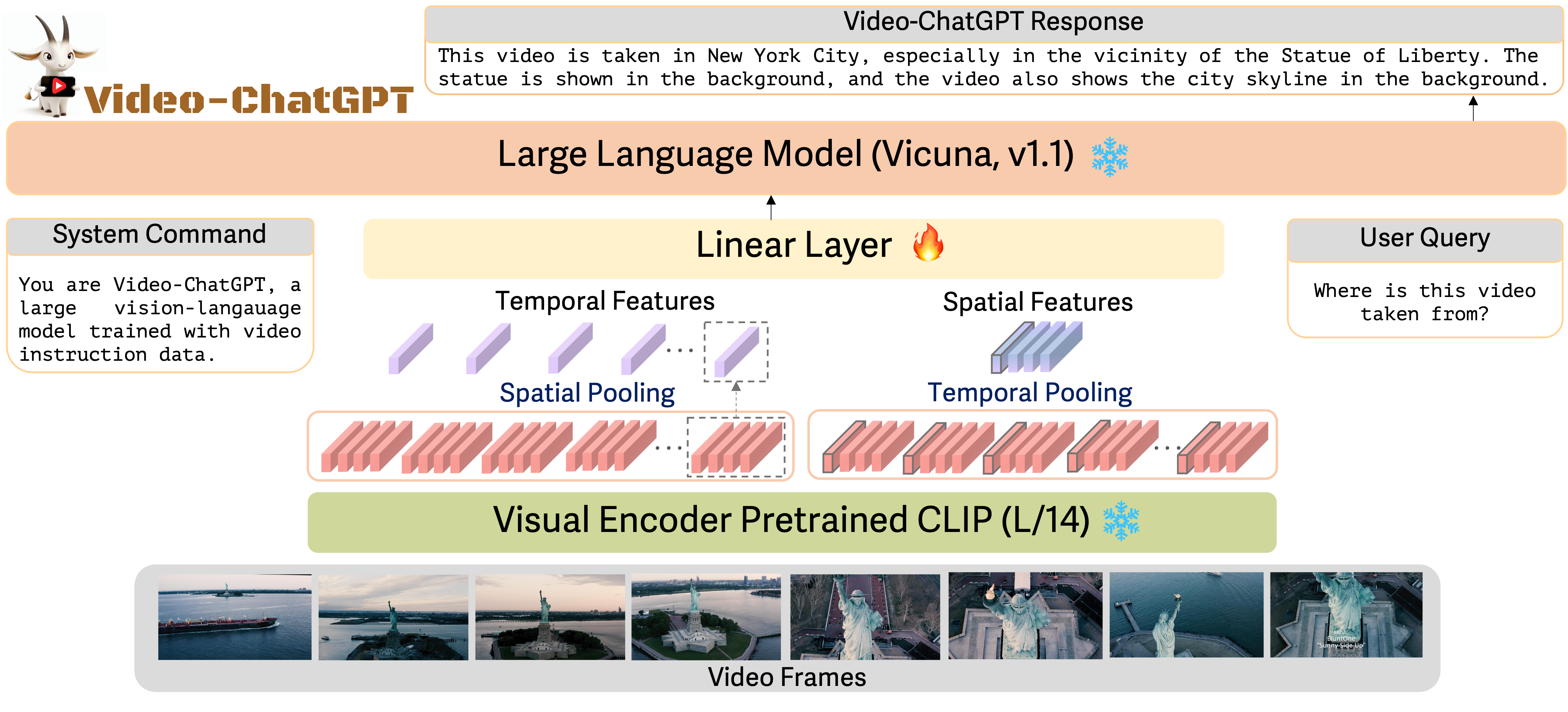
- 通过将 CLIP ViT-L/14 作为视觉编码器并以 Vicuna 作为语言解码器,架构一个视频扩展的VL模型。
- 通过指令微调创建并在 100k video-instruction 对上进行微调,同时保持大多数骨干组件冻结。
- 开发一个简单的适配器 g,将时空视频特征投射到 LLM 输入空间。
- 通过人机协作与半自动标注流程的混合方式生成丰富的视频指令数据。
- 提出一个覆盖正确性、细节、上下文、时序和一致性等方面的视频对话定量评估框架。
实验结果
研究问题
- RQ1视觉-语言模型在时空视频内容的理解和对话方面有多高的能力?
- RQ2在骨干网络冻结的情况下,轻量级适配器是否能实现与之竞争的视频对话性能?
- RQ3高质量、特定于视频的指令数据对开放式视频对话有何影响?
- RQ4我们如何在多项能力上量化基于视频的对话模型的优点与不足?
主要发现
- Video-ChatGPT 在多数据集上与同期模型相比取得了具有竞争力的零样本问答表现。
- 在 MSVD-QA、MSRVTT-QA、TGIF-QA 和 ActivityNet-QA 上,Video-ChatGPT 的准确率/分数高于 Video Chat 和 FrozenBiLM 基线。
- 由于对视频数据的指令微调,该模型展现出强烈的时间理解和上下文感知的回应。
- 一个包含人类辅助与半自动标注的 100k video-instruction 数据集提升了视频特定理解和对话能力。
- 本文首次引入定量化的视频对话评估框架,用于基准测试基于视频的对话模型。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。