[论文解读] VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
VideoCrafter1 提供两种开源扩散模型用于高质量视频生成:一个文本到视频(T2V)模型,产出电影级分辨率的视频;以及一个图像到视频(I2V)模型,在对给定图像保留内容的同时对其进行动画处理。
Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 imes 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.
研究动机与目标
- 推进开源视频生成,实现高质量文本到视频合成
- 实现以图像为条件的视频生成,保留输入内容与结构
- 探索具有时序注意力的潜在扩散技术以实现连贯视频
- 提供支持高分辨率视频生成的训练策略与数据集
- 提供工具与基准,促进社区采用与评估
提出的方法
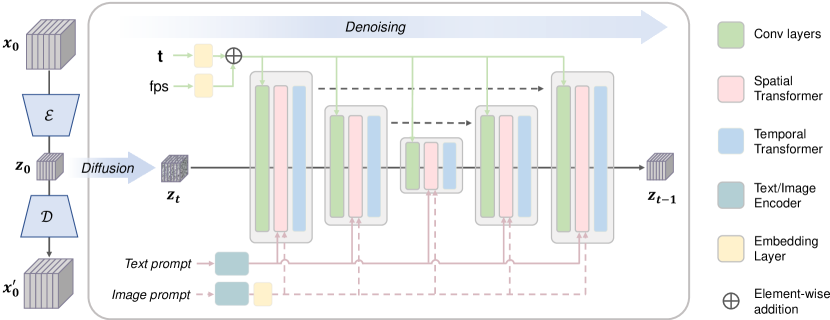
- 构建一个潜在视频扩散模型(LVDM),在潜在空间中使用视频 VAE 与视频扩散模型
- 将时序注意力层引入三维去噪 U-Net,以确保时序一致性
- 通过文本提示的跨注意力注入语义控制;使用 FPS/时序嵌入来控制运动速度
- 对于 I2V,从 CLIP 的图像编码器提取丰富的图像嵌入,并通过双重跨注意力将其与文本嵌入融合
- 在大规模图像和视频数据集上进行 T2V 训练,采用逐步分辨率策略(256×256 到 1024×576)
- 开发一个开源的 I2V 映射,将图像嵌入对齐到扩散模型的跨注意力空间

实验结果
研究问题
- RQ1开放源扩散模型如何实现高质量、电影分辨率的 T2V 视频生成?
- RQ2一个开源的 I2V 模型是否能够在实现运动的同时如实保留参考图像的内容与结构?
- RQ3哪些架构与训练策略能改善开源视频扩散模型的时序一致性和运动幅度?
- RQ4图像条件标记与全局语义标记在图像到视频条件下的表现有何差异?
- RQ5哪些数据集与训练方案能够在开源环境中实现稳健的高分辨率视频生成?
主要发现
- T2V 模型在开源框架中实现了高视觉质量并支持高分辨率视频生成
- I2V 模型旨在在实现动画的同时保留输入图像的内容和结构
- 丰富的图像嵌入(完整的 CLIP 图块标记)在图像条件视频生成中比全局语义标记更能提升保真度
- 双重跨注意力实现了在 I2V 生成中整合文本和图像输入,所需参数极少
- 潜在空间扩散结合时序注意力比某些基线在时序一致性和运动动态方面表现更好
- 开源模型在若干评估方面与商业对手具有竞争力,并且在持续时间和运动真实感方面还有改进空间
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。