[论文解读] VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
VideoFusion 引入一个分解的扩散过程用于视频生成,其中基础噪声在帧之间共享,残差噪声随时间变化,从而可以使用预训练的图像扩散模型作为基础生成器,在多个数据集上实现了最先进的结果。
A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to high-dimensional data spaces. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.
研究动机与目标
- 通过利用视频帧中的时间冗余,推动扩散模型在视频生成中的改进。
- 提出一个分解的扩散过程,将每帧噪声分成共享的基础噪声和随时间变化的残差噪声。
- 利用预训练的图像扩散模型作为基础生成器,将强烈的图像先验注入视频合成。
- 开发一个残差生成器,以在帧索引和文本/条件提示的条件下建模逐帧残差。
- 展示效率和可扩展性带来的好处,并分析在生成视频中控制内容与运动的因素。
提出的方法
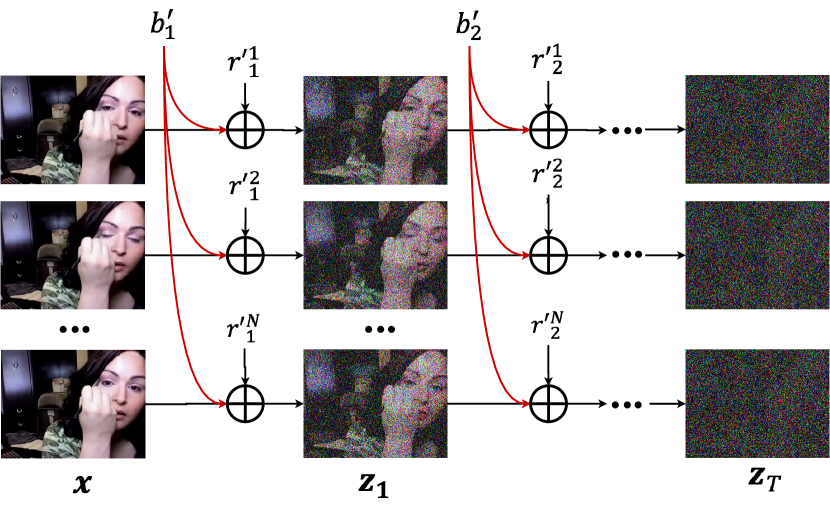
- 将每帧数据 x^i 分解为共享基 x^0 和残差 Delta x^i,使 x^i = sqrt(lambda^i) x^0 + sqrt(1 - lambda^i) Delta x^i。
- 将扩散噪声 epsilon_t^i 在帧间分解为共享基噪声 b_t 和残余噪声 r_t^i,使 z_t^i 可以表示为 x^0 的扩散和 Delta x^i 的扩散之和。
- 在所有帧之间共享基噪声 b_t,使 z_t^i 通过 b_t 相关,减轻去噪网络重建连贯视频的负担。
- 使用预训练的图像 DPM 作为基础生成器,从单帧估计基础噪声 z_phi^b(z^{floor(N/2)}_t, t),以及残差生成器 z_psi^r 估计逐帧残余噪声。
- 联合训练但对基础生成器在帧 i ≠ floor(N/2) 处停止梯度,以在保留图像先验的同时允许对视频数据进行微调。
- 采用 DDIM/DDPM 采样,分两步:先移除基础噪声,然后估计残余噪声以生成下一个潜在步骤。
![Figure 2 : Comparison between images generated from (a) independent noises; (b) noises with a shared base noise. Images of the same row are generated by the decoder of DALL-E 2 [ 25 ] with the same condition.](https://ar5iv.labs.arxiv.org/html/2303.08320/assets/x2.png)
实验结果
研究问题
- RQ1将扩散噪声分解为一个共享基础分量和一个逐帧特定的残差分量,是否可以提高视频扩散模型的时间一致性?
- RQ2利用预训练的图像扩散模型作为基础生成器,是否提供强先验以提升视频合成的质量和效率?
- RQ3应如何选择 lambda^i(每帧的基础噪声份额)以在保留内容与运动动态之间取得平衡?
- RQ4基础生成器与残差生成器的联合微调对视频生成性能有何影响?
- RQ5模型是否能够扩展到更长的序列和更高的分辨率,同时保持连贯性与质量?
主要发现
- VideoFusion 在多个数据集上实现了最先进的结果,在 16×64×64 和 16×128×128 分辨率下的 FVD 与 IS 指标都优于基于 GAN 的和基于扩散的基线。
- 在 UCF101(无条件,16×64×64):VideoFusion 获得 IS 71.67 和 FVD 139;在 16×128×128:IS 72.22 和 FVD 220。
- 在 Sky Time-lapse:FVD 47.0 和 KVD 5.3;在 TaiChi-HD:FVD 56.4 和 KVD 6.9。
- 与 VDM 重实现相比,由于共享基噪声和一个大型预训练基础生成器,内存显著降低(约 21.8% )、潜在延迟显著降低(约 57.5%)。
- 消融研究表明 lambda^i 参数对性能具有关键影响;中等值(如 0.5)在 IS/FVD 上优于太小或太大的值,并且带停止梯度的联合微调可以改善结果。
- 长序列生成(512 帧)在保持质量和连贯性方面可通过在改变残余噪声的同时保持基础噪声固定来实现。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。