[论文解读] VideoPrism: A Foundational Visual Encoder for Video Understanding
VideoPrism 是一个通用的冻结视频编码器,使用大量高质量字幕与嘈杂文本混合进行预训练,在分类、定位、检索、字幕生成和问答等大多数视频理解基准上实现最先进的结果。
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 31 out of 33 video understanding benchmarks. Our models are released at https://github.com/google-deepmind/videoprism.
研究动机与目标
- 促使需要一个真正基础的视频模型,能够在外观和运动理解之间取得平衡。
- 提出一个利用视频-文本对和仅视频数据的两阶段预训练策略。
- 证明一个冻结的视频编码器在多样化任务上,凭借极少的任务特定适应即可实现最先进的结果。
- 展示 VideoPrism 在通用视频任务和科学计算机视觉领域的有效性,以说明广泛的可推广性。
提出的方法
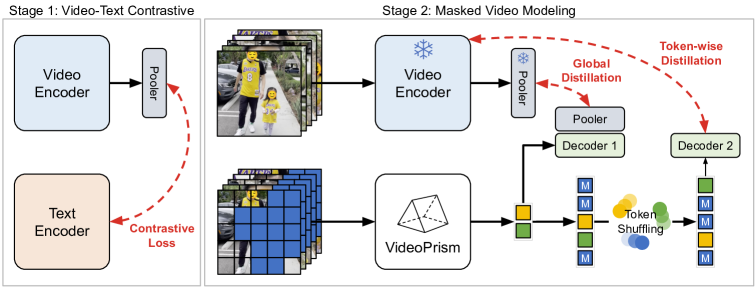
- 两阶段预训练:阶段 1 通过视频-文本对比学习学习语义视频嵌入。
- 阶段 2 在仅视频数据上进行改进的掩码视频建模,结合全局-局部蒸馏。
- 引入一个 token 洗牌方案,以防止在掩码建模过程中出现解码捷径。
- 使用第一阶段嵌入的全局蒸馏,以缓解灾难性遗忘。
- 基于 Vision Transformer 的架构,采用时空分解,空间编码器后不进行全局池化。
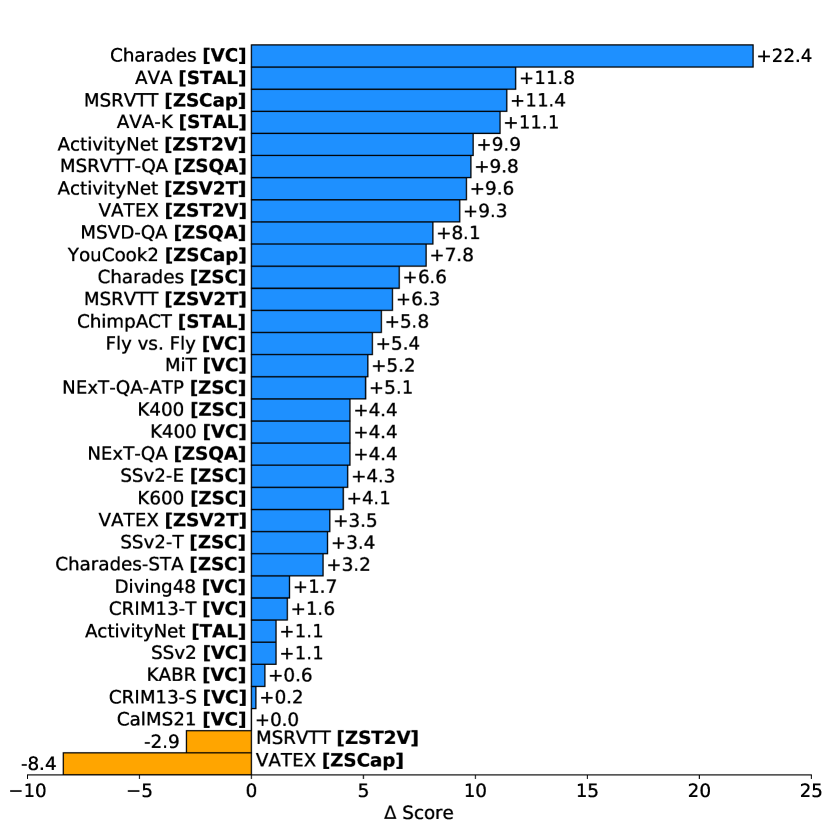
实验结果
研究问题
- RQ1是否可以用异质性的视频-文本数据和仅视频数据训练的单一冻结视频编码器,在广泛的视频理解任务上实现最先进的性能?
- RQ2带有全局-局部蒸馏和 token 洗牌的两阶段预训练方法是否提高了视频中的运动与外观理解?
- RQ3VideoPrism 在零样本视频-文本检索、字幕生成、问答以及科学领域数据集上的泛化能力有多强,而无需任务特定的微调?
- RQ4冻结编码器、仅训练任务头部就能在不同基准上获得具有竞争力的结果吗?
主要发现
- VideoPrism 在四个任务组的 33 项视频理解基准中有 30 项达到最先进水平。
- 冻结的 VideoPrism 变体(B 和 g)在 VideoGLUE 类基准和零-shot 任务上始终优于基线。
- 带有全局-局部蒸馏和 token 洗牌的两阶段预训练带来显著提升,特别是在以运动为中心的数据集如 SSv2 上。
- 零样本视频-文本检索和分类达到新记录,常常超越更大或具有额外模态的多模态模型。
- VideoPrism 展现出对 CV-for-science 数据集的强泛化能力,常常超过领域特定模型,尤其是在 base-scale 和 large-scale 变体中。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。