[论文解读] VioLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation
VioLA 是一个仅解码器的 Transformer,通过将语音转换为离散编解码器标记并使用任务和语言 ID 的多任务目标训练,统一语音与文本任务(ASR、MT、TTS、S2TT、S2ST)。
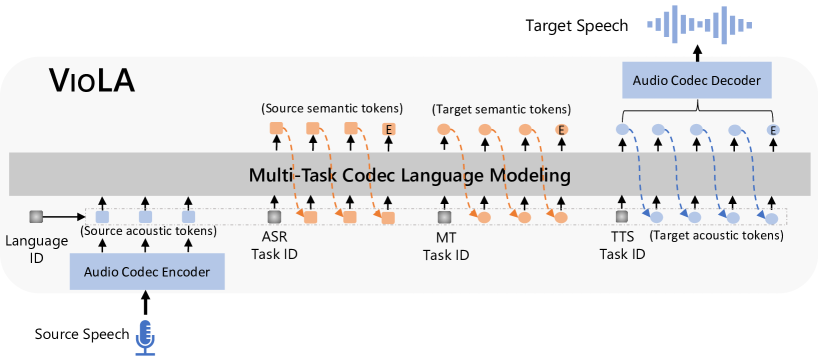
Recent research shows a big convergence in model architecture, training objectives, and inference methods across various tasks for different modalities. In this paper, we propose VioLA, a single auto-regressive Transformer decoder-only network that unifies various cross-modal tasks involving speech and text, such as speech-to-text, text-to-text, text-to-speech, and speech-to-speech tasks, as a conditional codec language model task via multi-task learning framework. To accomplish this, we first convert all the speech utterances to discrete tokens (similar to the textual data) using an offline neural codec encoder. In such a way, all these tasks are converted to token-based sequence conversion problems, which can be naturally handled with one conditional language model. We further integrate task IDs (TID) and language IDs (LID) into the proposed model to enhance the modeling capability of handling different languages and tasks. Experimental results demonstrate that the proposed VioLA model can support both single-modal and cross-modal tasks well, and the decoder-only model achieves a comparable and even better performance than the strong baselines.
研究动机与目标
- 激励单一的解码器模型覆盖跨模态的语音与文本任务。
- 将语音信号转换为离散编解码器标记,使所有任务均视为标记序列问题。
- 结合任务ID和语言ID以区分语言和任务。
- 证明一个统一的解码器能够在多项语音任务上达到或超过强基线。
提出的方法
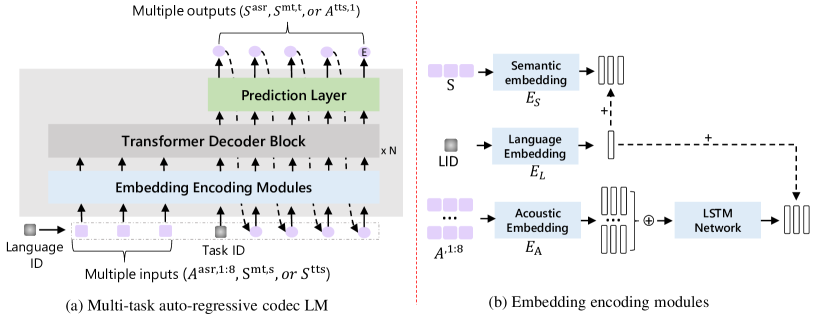
- 以自回归编解码器 Transformer 语言模型作为核心网络。
- 通过 EnCodec 将语音转换为 8 层声学标记序列,文本转换为音素序列。
- 通过前置网络嵌入模块和 Transformer 解码器融合语义与声学标记。
- 通过在各任务上最大化 p(y|x,θ) 的多任务目标来训练,以支持 ASR、MT、TTS。
- 结合任务ID和语言ID以对模型进行任务和语言的条件化。
- 对于 TTS,采用非自回归编解码 LM 来生成所有层的声学标记,类似于 VALL-E X。
实验结果
研究问题
- RQ1在基于编解码器的框架中,单一解码器模型能否完成 ASR、MT、TTS 以及跨模态翻译?
- RQ2将语音编码为离散的编解码标记是否能在多项语音任务中实现有效的标记序列建模?
- RQ3模型大小和声学标记层数对各任务性能的影响如何?
- RQ4任务ID和语言ID如何影响跨语言和跨任务的能力?
主要发现
- VioLA(18L)在 WMT2020 MT(56.97)上实现了处于领先地位的 BLEU,参数量与 AED 基线相近。
- 在 ASR 上,18 层的 VioLA 达到 PER 11.36,接近 AED 性能并优于某些解码器仅基线。
- 在 S2TT 中,基于编解码的级联 LM 配合 VioLA 的 BLEU 达到 55.70–55.85,与基于 Fbank 的级联 AED 模型相当,但参数更少。
- 零样本英语 TTS 和跨语言 TTS 相较于 VALL-E X 显示出更高的说话人相似度和自然度,在 WER 降低和 SN 分数方面有 SAL 的提升。
- 每帧声学代码层数的增加显著提升 ASR 性能,PER 显著下降。
- 在嵌入模块中加入 LSTM 进一步提升 ASR 和 TTS 性能,改善解码质量。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。