[论文解读] Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
VAR 将图像自回归重塑为下一尺度预测,允许自上而下、并行的令牌 Map 生成;在 ImageNet 256×256 上比扩散 Transformer 有更快的推理速度且性能更好。
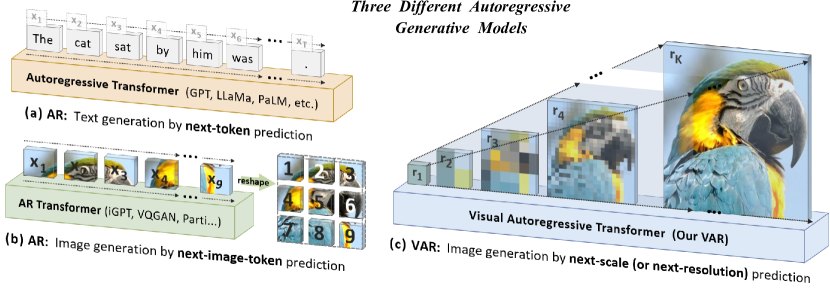
We present Visual AutoRegressive modeling (VAR), a new generation paradigm that redefines the autoregressive learning on images as coarse-to-fine "next-scale prediction" or "next-resolution prediction", diverging from the standard raster-scan "next-token prediction". This simple, intuitive methodology allows autoregressive (AR) transformers to learn visual distributions fast and generalize well: VAR, for the first time, makes GPT-like AR models surpass diffusion transformers in image generation. On ImageNet 256x256 benchmark, VAR significantly improve AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.73, inception score (IS) from 80.4 to 350.2, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability. Scaling up VAR models exhibits clear power-law scaling laws similar to those observed in LLMs, with linear correlation coefficients near -0.998 as solid evidence. VAR further showcases zero-shot generalization ability in downstream tasks including image in-painting, out-painting, and editing. These results suggest VAR has initially emulated the two important properties of LLMs: Scaling Laws and zero-shot task generalization. We have released all models and codes to promote the exploration of AR/VAR models for visual generation and unified learning.
研究动机与目标
- 受大型语言模型(LLMs)和人类视觉层级启发,提出一个可扩展的图像自回归范式。
- 开发多尺度标记化和下一尺度自回归训练方案,以保持空间结构并提升效率。
- 展示与扩散模型相比的尺度定律、零-shot 泛化,以及具竞争力甚至更优的图像质量。
提出的方法
- 引入多尺度 VQVAE 标记化,在不断增高的分辨率下生成 K 个令牌映射。
- 定义下一尺度自回归建模,其中 p(r1,r2,...,rK)=Πp(rk|r1,...,rk-1) 并行生成每个 rk。
- 使用 GPT-2 风格的解码器仅 Transformer,带 AdaLN 进行条件化,以及用于宽度、深度和 dropout 的简单缩放规则。
- 采用 VQVAE 重建的复合损失和 VAR 的标准交叉熵(token)损失进行训练。
- 证明 VAR 将生成复杂度降低到 O(n4),并在每个尺度内实现并行令牌生成。

实验结果
研究问题
- RQ1一个粗细粒度的多尺度自回归框架是否能在图像生成质量和速度上相对于栅格扫描自回归方法有所改进?
- RQ2VAR 模型是否表现出类似于大型语言模型的尺度定律和零-shot 泛化?
- RQ3多尺度令牌映射如何影响空间局部性、学习动态和数据效率在视觉自回归中的作用?
- RQ4VAR 模型在 FID/IS、速度和可扩展性方面是否具有与基于扩散的 Transformer 相竞争或更优?
主要发现
- VAR 在 ImageNet 256×256 上达到 FID 1.80 和 IS 356.4,参数量为 2B,推理速度比基线自回归模型快 20×。
- VAR 在多个模型规模上超越 Diffusion Transformer (DiT) 在 FID、IS、数据效率和可扩展性方面的表现。
- VAR 展现出与 LLMs 相似的模型大小和计算的幂律尺度定律,表明随着模型变大和训练计算增加,性能提升。
- 在不需要特殊架构改动的情况下,零-shot 能力在修补、外部填充和编辑任务中得到体现。
- 基于 VAR 的模型在质量和效率方面显著优于传统自回归基线(如基于 VQGAN 的自回归)。
- 在 512×512 合成中,VAR 与 d36 达到 FID 2.63 和 IS 303.2,时间具有竞争力。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。