[论文解读] Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings
Visual Chain-of-Thought (VCoT) 将 chain-of-thought 提示扩展到视觉-语言领域,通过生成与选择多模态填充来弥合序列数据中的逻辑鸿沟,通过数据增强提升下游推理任务,如视觉讲故事和 WikiHow 摘要。
Recent advances in large language models elicit reasoning in a chain-of-thought that allows models to decompose problems in a human-like fashion. Though this paradigm improves multi-step reasoning ability in language models, it is limited by being unimodal and applied mainly to question-answering tasks. We claim that incorporating visual augmentation into reasoning is essential, especially for complex, imaginative tasks. Consequently, we introduce VCoT, a novel method that leverages chain-of-thought prompting with vision-language grounding to recursively bridge the logical gaps within sequential data. Our method uses visual guidance to generate synthetic multimodal infillings that add consistent and novel information to reduce the logical gaps for downstream tasks that can benefit from temporal reasoning, as well as provide interpretability into models' multi-step reasoning. We apply VCoT to the Visual Storytelling and WikiHow summarization datasets and demonstrate through human evaluation that VCoT offers novel and consistent synthetic data augmentation beating chain-of-thought baselines, which can be used to enhance downstream performance.
研究动机与目标
- 推动将 chain-of-thought 推理从文本扩展到多模态序列,以解决逻辑鸿沟。
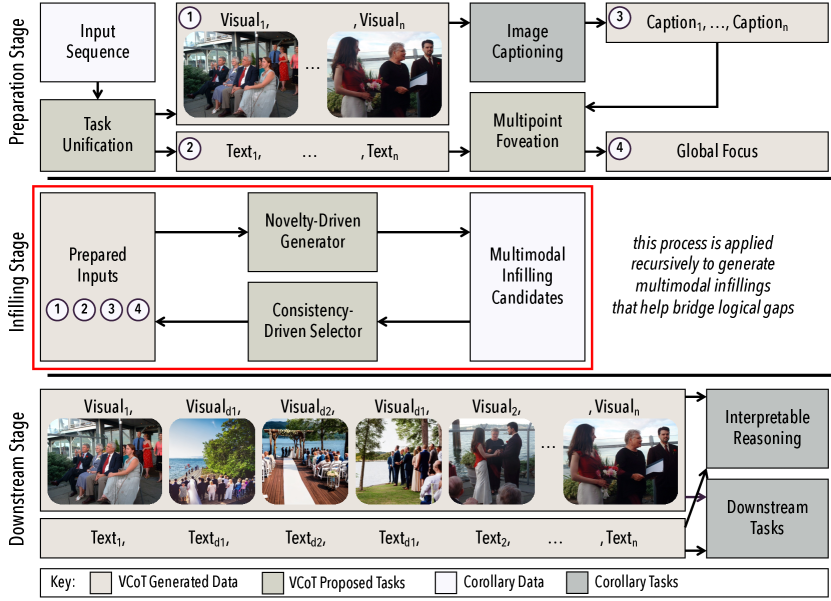
- 提出一个免训练的、迭代生成与选择框架,用于创建合成的文本-视觉填充。
- 在为下游序列任务进行数据增强的同时,提供对多步推理的可解释洞见。
提出的方法
- 通过对仅文本数据使用 Stable Diffusion 生成候选视觉图像,并用 CLIP 选择与给定文本最相似的视觉图像,将序列统一为文本-视觉对。
- 通过多点聚焦(multipoint foveation)从输入序列中提取全局焦点,以引导一致的填充生成。
- 使用以新颖性和一致性为驱动的递归生成多模态填充,受 GPT-3.5 和视觉定位引导。
- 使用基于 CLIP 的相似度来选择最一致的文本与视觉填充,且固定递归深度(depth-limit = 2)。
- 用人类评估来评估填充,强调新颖性、一致性、连贯性和描述性。

实验结果
研究问题
- RQ1从可视与文本上下文生成的多模态填充,是否能够弥合序列数据中的逻辑鸿沟以提升下游任务?
- RQ2与单模态的 chain-of-thought 基线相比,VCoT 填充是否在视觉-语言任务中提升一致性与新颖性?
- RQ3合成的多模态数据增强对视觉讲述和 WikiHow 风格摘要的下游表现有何影响?
- RQ4定位(grounding)和聚焦(foveation)在维持跨填充的一致性中起到何种作用?
主要发现
- 相比 CoT 和 CoI 基线,VCoT 填充在新颖性和一致性方面被人工评估者给予更高评分。
- VCoT 相对于基线在 WikiHow 摘要和视觉讲述的下游性能有所提升,在 WikiHow 上的新颖性提升更强,在 Vist 上的一致性更好。
- 一致性受多点聚焦和 CLIP 指导选择的帮助,而新颖性通过 GPT-3.5 驱动的文本填充生成和 Stable Diffusion 生成的视觉图像实现。
- VCoT 提供了对推理过程的多模态可解释性,并充当减少序列推理中的逻辑跃迁的数据增强。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。