[论文解读] Visual Instruction Tuning
本文提出 LLaVA,一种通过 GPT-4 生成的视觉-语言数据来指导视觉编码器和大型语言模型的多模态模型,在强大多模态对话方面表现突出,并在与 GPT-4 结合时在 ScienceQA 上达到SOTA。
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
研究动机与目标
- 激发将指令微调扩展到视觉-语言模型,以实现通用的视觉助手。
- 提供一种可扩展的管线,使用语言模型生成多模态指令遵循数据。
- 开发并评估 LLaVA,一种将视觉编码器与语言模型相结合的大型多模态模型。
- 创建并发布用于对话与推理任务中多模态指令遵循的基准测试(LLaVA-Bench)。
提出的方法
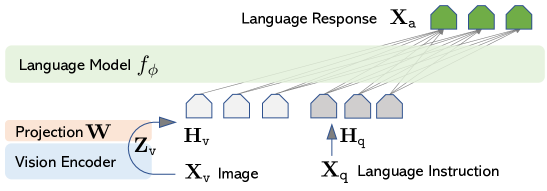
- 通过可训练的投影 W 将 CLIP 视觉编码器连接到 Vicuna 语言模型,以产生视觉令牌。
- 使用 GPT-4(以及更早的 ChatGPT)从图片-文本数据中生成 158K 个多模态指令遵循样本,形式包括:会话、详细描述和复杂推理。
- 两阶段训练:阶段1 通过用 CC3M 的子样本将图像特征与 LLM 嵌入对齐来预训练一个视觉分词器;阶段2 在生成数据上与 W 和 φ(LM)端到端微调。
- 使用多模态对话数据进行训练,并在多模态对话和 ScienceQA 上进行评估;与 GPT-4 集成以获得更好的结果。
实验结果
研究问题
- RQ1GPT-4 生成的视觉-语言数据是否能实现对多模态模型的有效视觉指令微调?
- RQ2将 CLIP-Vicuna 架构与 GPT-4 生成的数据管线结合,在开放式多模态任务上能有多好表现?
- RQ3将 LLaVA 与 GPT-4 结合是否在多模态推理基准上实现最前沿结果?
- RQ4不同类型的指令遵循数据(对话、详细描述、复杂推理)在多模态对齐中的价值如何?
主要发现
| 模型 | 对话 | 详细描述 | 复杂推理 | 全部 |
|---|---|---|---|---|
| OpenFlamingo | 19.3 ± 0.5 | 19.0 ± 0.5 | 19.1 ± 0.7 | 19.1 ± 0.4 |
| BLIP-2 | 54.6 ± 1.4 | 29.1 ± 1.2 | 32.9 ± 0.7 | 38.1 ± 1.0 |
| LLaVA | 57.3 ± 1.9 | 52.5 ± 6.3 | 81.7 ± 1.8 | 67.3 ± 2.0 |
| LLaVA † | 58.8 ± 0.6 | 49.2 ± 0.8 | 81.4 ± 0.3 | 66.7 ± 0.3 |
- LLaVA 在对未见图像和指令的多模态对话方面表现强劲,接近多模态 GPT-4。
- 在一个合成的多模态指令遵循数据集上,LLaVA 相对于 GPT-4 的相对分数为 85.1%。
- 在 ScienceQA 上使用 GPT-4 集成进行微调后,达到 92.53% 的新最先进准确率。
- LLaVA-Bench(In-the-Wild)显示出指令微调带来的显著提升,三种数据类型均提供最佳综合性能,达到 85.1%。
- 消融研究表明预训练和模型规模对结果有实质性影响,13B 的 LLaVA 模型在 ScienceQA 上达到 90.92%,并与 GPT-4 结合时进入 SOTA。
![Table 3 : Example prompt from GPT-4 paper [ 36 ] to compare visual reasoning and chat capabilities. Compared to BLIP-2 [ 28 ] and OpenFlamingo [ 5 ] , LLaVA accurately follows the user’s instructions, instead of simply describing the scene. LLaVA offers a more comprehensive response than GPT-4. Even](https://ar5iv.labs.arxiv.org/html/2304.08485/assets/figures/img_extreme_ironing.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。