QUICK REVIEW
[论文解读] VoiceFilter: Targeted Voice Separation by Speaker-Conditioned Spectrogram Masking
Quan Wang, Hannah Muckenhirn|arXiv (Cornell University)|Oct 11, 2018
Speech and Audio Processing参考文献 21被引用 49
一句话总结
本文提出 VoiceFilter,这是一个两网络系统,使用目标说话人嵌入来执行说话人条件化频谱掩蔽,能有效从多说话人混合中提取目标声音,并在对清洁语音影响最小的情况下提高 ASR WER。
ABSTRACT
In this paper, we present a novel system that separates the voice of a target speaker from multi-speaker signals, by making use of a reference signal from the target speaker. We achieve this by training two separate neural networks: (1) A speaker recognition network that produces speaker-discriminative embeddings; (2) A spectrogram masking network that takes both noisy spectrogram and speaker embedding as input, and produces a mask. Our system significantly reduces the speech recognition WER on multi-speaker signals, with minimal WER degradation on single-speaker signals.
研究动机与目标
- 在事先不知道说话人数的情况下,激发目标语音分离的动机。
- 开发一个说话人编码器,为目标说话人生成鲁棒的嵌入。
- 设计一个频谱掩蔽网络,利用目标说话人嵌入来抑制干扰。
- 在多说话人数据上展示 WER 的改进,同时保持单说话人性能。
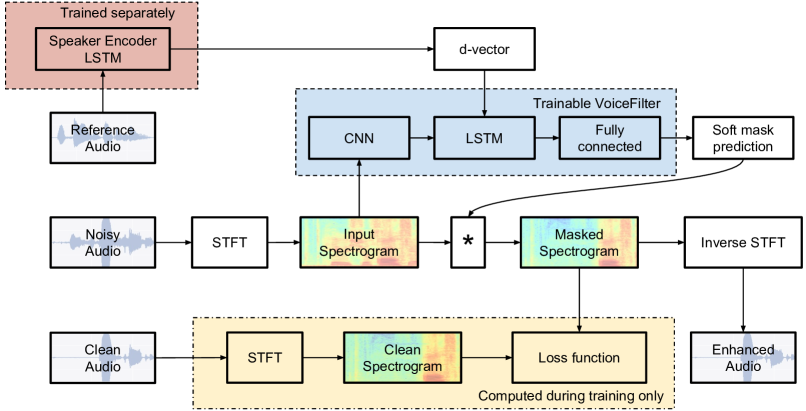
提出的方法
- 从对数梅尔特征训练一个3层 LSTM 说话人编码器,产生256维 d-vector。
- 训练一个频谱掩蔽网络,使其以目标说话人 d-vector 和嘈杂幅度谱为条件来预测一个软掩模。
- 将 d-vector 注入掩蔽网络,在卷积层和 LSTM 层之间,以保持时频处理。
- 通过增强与目标干净幅度谱之间的重建损失来优化掩蔽,再使用原始相位重建波形。
- 在训练时以 16 kHz 处理 3 秒段音频。
- 使用词错误率(WER)和失真源比(SDR)进行评估。
实验结果
研究问题
- RQ1目标说话人嵌入是否能够在不知道干扰说话人数的情况下实现端到端分离?
- RQ2相较于传统分离方法,说话人条件化如何影响 WER 和 SDR?
- RQ3不同时间模型(无 LSTM、单向 LSTM、双向 LSTM)对性能的影响是什么?
- RQ4在更大且多样化的数据集上训练是否能跨领域泛化(从 LibriSpeech 到 VCTK 等)?
主要发现
| 模型 | 数据集 | 清洁 WER (%) | 嘈杂 WER (%) |
|---|---|---|---|
| 无 VoiceFilter | LibriSpeech | 10.9 | 55.9 |
| VoiceFilter: 无 LSTM | LibriSpeech | 12.2 | 35.3 |
| VoiceFilter: LSTM | LibriSpeech | 12.2 | 28.2 |
| VoiceFilter: 双向 LSTM | LibriSpeech | 11.1 | 23.4 |
| 无 VoiceFilter | VCTK | 6.1 | 60.6 |
| 在 VCTK 上训练 | VCTK | 21.1 | 37.0 |
| 在 LibriSpeech 上训练 | VCTK | 5.9 | 34.3 |
- 双向 LSTM 的 VoiceFilter 在嘈杂的 LibriSpeech 数据上取得最佳 WER(23.4%,相比单向 LSTM 的 28.2%,无 LSTM 的 35.3%)。
- VoiceFilter 将 LibriSpeech 两说话人混合的嘈杂 WER 从 55.9% 降至 23.4%(LibriSpeech 训练)。
- 在 LibriSpeech 上,嘈杂 WER 的改进在最佳模型下实现相对降低 58.1%,而清洁 WER 接近清洁基线(11.1% vs 10.9%)。
- 在 VCTK 上,在 LibriSpeech 训练将嘈杂 WER 从 60.6% 提升到 34.3%,清洁 WER 略有下降(5.9% vs 6.1%);在 VCTK 上训练则产生更高的清洁 WER(21.1%)。
- SDR 结果与 WER 趋势一致;在 LibriSpeech 上,双向 LSTM 达到最高的均值/中位数 SDR(17.9 dB / 12.6 dB)。
- 使用说话人嵌入的 VoiceFilter 优于置换不变损失基线,显示了目标说话人条件化的好处。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。