[论文解读] VRSBench: A Versatile Vision-Language Benchmark Dataset for Remote Sensing Image Understanding
VRSBench 提供一个大规模、经人工验证的遥感视觉-语言基准数据集,包含 29,614 张图像、字幕、对象引用,以及 123,221 个 VQA 对,评估内容涵盖字幕生成、定位/对齐和 VQA。
We introduce a new benchmark designed to advance the development of general-purpose, large-scale vision-language models for remote sensing images. Although several vision-language datasets in remote sensing have been proposed to pursue this goal, existing datasets are typically tailored to single tasks, lack detailed object information, or suffer from inadequate quality control. Exploring these improvement opportunities, we present a Versatile vision-language Benchmark for Remote Sensing image understanding, termed VRSBench. This benchmark comprises 29,614 images, with 29,614 human-verified detailed captions, 52,472 object references, and 123,221 question-answer pairs. It facilitates the training and evaluation of vision-language models across a broad spectrum of remote sensing image understanding tasks. We further evaluated state-of-the-art models on this benchmark for three vision-language tasks: image captioning, visual grounding, and visual question answering. Our work aims to significantly contribute to the development of advanced vision-language models in the field of remote sensing. The data and code can be accessed at https://github.com/lx709/VRSBench.
研究动机与目标
- 解决现有遥感视觉-语言数据集的局限性(单一任务、对象细节不足、质量控制问题)
- 提供一个大型、统一的数据集,包含详细字幕、对象引用和开放式 VQA
- 使遥感领域的字幕生成、定位和 VQA 的视觉-语言模型训练与评估成为可能
- 提出一个半自动数据收集流程,结合人工验证以确保注释质量
- 提供三个基准(字幕生成、定位、VQA)并对最先进模型进行基线评估
提出的方法
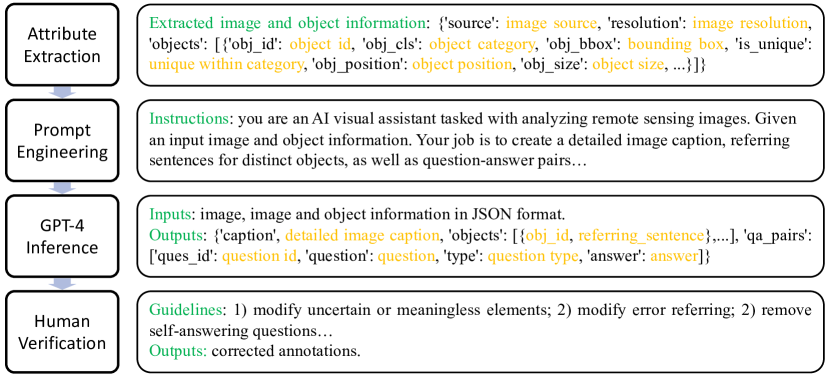
- 提出一个含四个步骤的半自动数据收集流程:属性提取、提示工程、GPT-4 推断,以及人工验证
- 以 DOTA-v2 和 DIOR 作为对象属性和边界框的来源,以实现带定向边界框(OBB)的定位
- 为 GPT-4V 设计谨慎的提示语以生成字幕、对象指称句和问答对,随后进行人工验证
- 提供注释,包括详细字幕、每张图像 1–5 条对象指称句,以及每张图像 3–10 条 VQA 对
- 构建三个基准(VRSBench-Cap、VRSBench-Ref、VRSBench-VQA),并对基线模型在 VRSBench 上进行微调评估
- 使用标准评估指标进行评估(字幕生成使用 BLEU、ROUGE_L、METEOR、CIDEr;定位使用 Acc@IoU;VQA 按问题类型的准确率)

实验结果
研究问题
- RQ1在 VRSBench 上评估时,当前的视觉-语言模型在遥感领域的详细字幕、定位和 VQA 任务上的表现如何?
- RQ2在 VRSBench 上对通用视觉-语言模型进行微调,是否能显著提升字幕、定位和 VQA 的性能?
- RQ3在遥感图像的定位和 VQA 任务中,包含显式对象信息(属性、边界框)对结果的相对影响有多大?
- RQ4当提示中不包含显式对象信息时,GPT-4V 在这些任务上的表现如何,与在 VRSBench 上训练的模型相比?
主要发现
- VRSBench 使对遥感图像在字幕生成、定位和 VQA 三个任务上的大规模评估成为可能。
- 微调后的 LVMs(如 LLaVA-1.5)在字幕方面获得最高指标(BLEU-1 48.1,CIDEr 33.9),字幕平均 52 词。
- GPT-4V 在字幕和 VQA 上表现强劲(字幕:BLEU-1 37.2,CIDEr 19.1;VQA 平均 65.6),但在未提供对象属性时对定位的性能较弱。
- 定位结果显示微调模型优于基线,其中唯一对象指称比非唯一对象更容易(例如 GeoChat 在某些设置下总体 Acc@0.5 为 39.6%)。
- VQA 结果表明在 VRSBench 上微调带来显著提升(GeoChat w ft 的平均准确率 60.6%;GPT-4V 平均达到 65.6%),
- 该数据集包含 29,614 张图像,29,614 条字幕,52,472 条指称句,和 123,221 条 VQA 对,使用 512×512 RGB 图像。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。