[论文解读] Vulnerability Detection with Code Language Models: How Far Are We?
本文评估代码语言模型在漏洞检测方面的能力,揭示现有基准的数据质量与评估缺陷,推出具严格标注与去重的 PrimeVul,并显示当前模型在真实场景下表现较差。
In the context of the rising interest in code language models (code LMs) and vulnerability detection, we study the effectiveness of code LMs for detecting vulnerabilities. Our analysis reveals significant shortcomings in existing vulnerability datasets, including poor data quality, low label accuracy, and high duplication rates, leading to unreliable model performance in realistic vulnerability detection scenarios. Additionally, the evaluation methods used with these datasets are not representative of real-world vulnerability detection. To address these challenges, we introduce PrimeVul, a new dataset for training and evaluating code LMs for vulnerability detection. PrimeVul incorporates a novel set of data labeling techniques that achieve comparable label accuracy to human-verified benchmarks while significantly expanding the dataset. It also implements a rigorous data de-duplication and chronological data splitting strategy to mitigate data leakage issues, alongside introducing more realistic evaluation metrics and settings. This comprehensive approach aims to provide a more accurate assessment of code LMs' performance in real-world conditions. Evaluating code LMs on PrimeVul reveals that existing benchmarks significantly overestimate the performance of these models. For instance, a state-of-the-art 7B model scored 68.26% F1 on BigVul but only 3.09% F1 on PrimeVul. Attempts to improve performance through advanced training techniques and larger models like GPT-3.5 and GPT-4 were unsuccessful, with results akin to random guessing in the most stringent settings. These findings underscore the considerable gap between current capabilities and the practical requirements for deploying code LMs in security roles, highlighting the need for more innovative research in this domain.
研究动机与目标
- 分析现有漏洞检测数据集和基准的不足。
- 提出 PrimeVul 以高标注准确性标注和去重以减少数据泄露。
- 引入包括 VD-S 和配对函数评估在内的现实评估指南。
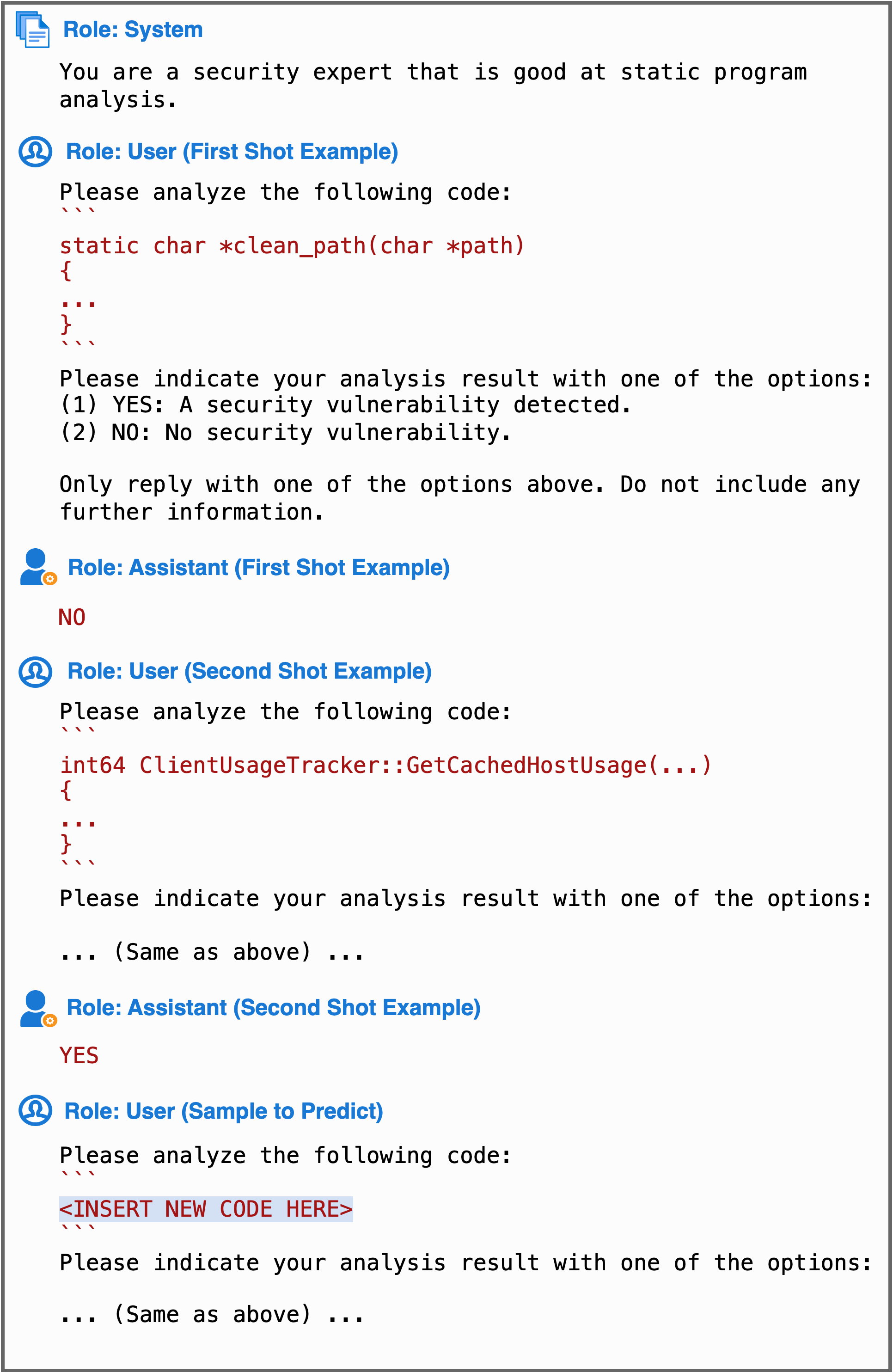
- 在 PrimeVul 上对多种开源代码语言模型进行实证评估,以建立现实的性能基线。
提出的方法
- 批判性分析现有 vd 基准的数据收集、标注准确性和重复性。
- 使用两种标注技术(PrimeVul - OneFunc 和 PrimeVul - NVDCheck)构建 PrimeVul,并进行彻底去重。
- 采用按时间顺序的训练/验证/测试划分以降低泄漏并引入 VD-S 和配对函数评估。
- 在现实设定下对多种开源代码 LMs 进行微调和评估,并在 PrimeVul 上筛选出 LLM。
- 报告包括准确率、F1、VD-S 和成对结果等指标,以评估实际用途。
实验结果
研究问题
- RQ1RQ1: 开源代码语言模型在 PrimeVul 上的表现如何?
- RQ2RQ2: 先进的训练技术是否能够提升漏洞检测性能?
- RQ3RQ3: 更大语言模型(LLMs)是否能提升漏洞检测性能?
主要发现
- 现有基准在现实设置下高估了代码 LM 漏洞检测的性能。
- PrimeVul 含有 6,968 个漏洞函数和 228,800 个无害函数,覆盖 140 个 CWE,标注准确性与人工基准相当。
- 在 PrimeVul 上评估时,代码 LMs 表现存在显著差距(例如在 BigVul 得分为 68.26% 的模型,在 PrimeVul 上的 F1 降至 3.09%)。
- 高级训练技术带来仅有边际增益;GPT-3.5 和 GPT-4 的结果并非在严格设置下更为可靠,甚至可能类似于随机猜测。
- 新评估指标(VD-S)和配对函数评估揭示传统的准确率/F1 指标未能捕捉的弱点。
- 时间顺序的数据划分减轻泄漏并更好地反映现实世界的模型部署约束。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。