[论文解读] We're Different, We're the Same: Creative Homogeneity Across LLMs
该研究比较来自广泛一组 LLM 与人类的创造性输出,使用标准化的创造力测试,发现 LLM 的回答在模型间显著更同质化,而人类在个体间的回答则不然。
Numerous powerful large language models (LLMs) are now available for use as writing support tools, idea generators, and beyond. Although these LLMs are marketed as helpful creative assistants, several works have shown that using an LLM as a creative partner results in a narrower set of creative outputs. However, these studies only consider the effects of interacting with a single LLM, begging the question of whether such narrowed creativity stems from using a particular LLM -- which arguably has a limited range of outputs -- or from using LLMs in general as creative assistants. To study this question, we elicit creative responses from humans and a broad set of LLMs using standardized creativity tests and compare the population-level diversity of responses. We find that LLM responses are much more similar to other LLM responses than human responses are to each other, even after controlling for response structure and other key variables. This finding of significant homogeneity in creative outputs across the LLMs we evaluate adds a new dimension to the ongoing conversation about creativity and LLMs. If today's LLMs behave similarly, using them as a creative partners -- regardless of the model used -- may drive all users towards a limited set of "creative" outputs.
研究动机与目标
- 评估作为一个整体的 LLM 相较于人类,在创造性输出中的变异性是更多、更少,还是相似。
- 确定跨 LLM 的同质性是否在多种模型家族和提示中持续存在。
- 将 LLM 与人类创造性输出中的内容相似性与结构相似性区分开来。
提出的方法
- 使用标准化创造力测试(AUT、Forward Flow、DAT)来获取来自人类和 7+ 种以上多样化 LLM 的创造性响应。
- 使用自动嵌入(GloVe)和余弦距离来量化新颖性,计算个体原创性。
- 通过全对余弦距离,测量嵌入响应的语义相似性来评估群体层面的变异性。
- 使用 Welch’s t-tests 对原创性和变异性差异进行比较,p < 0.01。
- 通过测试多种 AUT 提示版本并筛选词长/分布来控制回答结构。
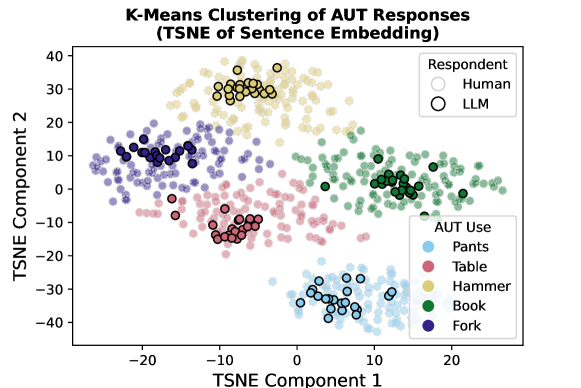
- 使用 TSNE 和聚类对回答空间进行可视化,以支持变异性发现。
实验结果
研究问题
- RQ1LLMs 与人类在 AUT、Forward Flow、和 DAT 上的创造性输出的平均原创性是否存在差异?
- RQ2当对同一提示作出反应时,LLM 的输出在不同模型之间是否比人类在不同人之间更为同质?
- RQ3当仅限于不同模型家族或调整提示结构时,跨 LLM 的同质性是否仍然存在?
- RQ4提示工程能否减轻或逆转 LLM 之间的创造力同质化?
主要发现
- LLMs 在 AUT 和 DAT 的原创性上略胜于人类,而人类在 Forward Flow 上略胜于 LLM。
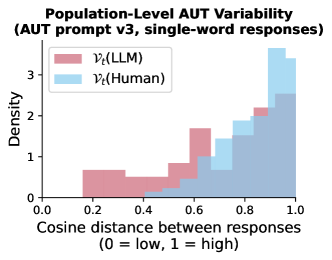
- 在各测试中,LLMs 的回答在群体层面的变异性显著低于人类,表明输出更同质。
- 提示工程可以改变 LLM 的创造力和变异性,但总体上人类仍然更具变异性;甚至只有一个单词的 AUT 回应也显示出 LLM 的变异性下降。
- 词汇重叠分析显示 LLM 在各回答中共享更多词汇内容,导致更高的语义相似性。
- 控制分析显示同质性在考虑 AUT 回应结构以及不同模型家族之间比较时仍然存在。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。