[论文解读] WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition
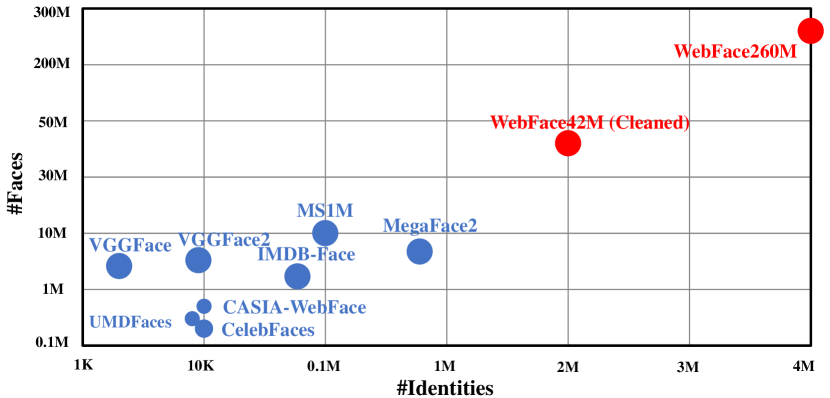
本文提出 WebFace260M(4M identities,260M faces)及其经 CAST 清理的对应版本 WebFace42M(2M identities,42M faces),并引入 FRUITS 受时限评估,以研究百万级人脸识别和分布式训练。
In this paper, we contribute a new million-scale face benchmark containing noisy 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name list and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical scenarios, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a test set are constructed to comprehensively evaluate face matchers. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Empowered by WebFace42M, we reduce relative 40% failure rate on the challenging IJB-C set, and ranks the 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with public training set. Furthermore, comprehensive baselines are established on our rich-attribute test set under FRUITS-100ms/500ms/1000ms protocol, including MobileNet, EfficientNet, AttentionNet, ResNet, SENet, ResNeXt and RegNet families. Benchmark website is https://www.face-benchmark.org.
研究动机与目标
- 通过创建百万级训练数据来弥合学术界与产业界在人脸识别领域的数据差距。
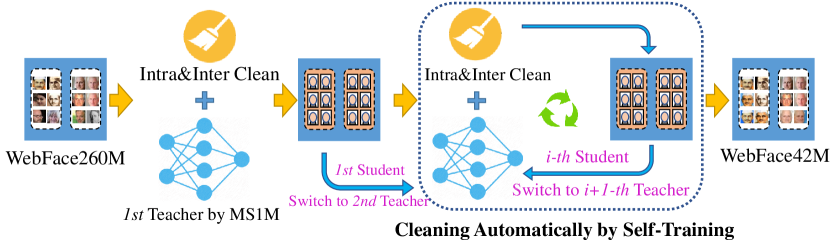
- 开发可扩展的自动清洗流水线(CAST),从嘈杂的网络数据中生成高质量的训练集。
- 提出 FRUITS,一种受时限约束的评估协议,以及一个丰富的测试集,以反映现实世界部署场景。
- 展示百万级训练和分布式训练对大型和轻量级主干网络的收益。
- 在 FRUITS 协议下提供跨架构的全面基线,为未来研究提供指导。
提出的方法
- 收集一个包含 4M 个名人姓名的名单,并从网上下载 260M 张图片。
- 使用自训练清洗(CAST)流水线对 WebFace260M 进行清洗,以获得 WebFace42M。
- 使用分布式框架对模型进行训练,在大规模数据上实现近线性加速。
- 设计 FRUITS(Face Recognition Under Inference Time conStraint),提供 100/500/1000 ms 轨道以及丰富的属性测试集。
- 在 FRUITS 及标准基准上评估多种主干网络(如 ResNet-100、ResNet-14)和损失函数(CosFace、ArcFace、CurricularFace)。
实验结果
研究问题
- RQ1在时限评估下,训练数据规模(WebFace260M 与 WebFace42M 及其子集)如何影响识别性能?
- RQ2CAST 在清洗大规模嘈杂网络数据以用于高质量人脸识别训练方面有多有效?
- RQ3在 FRUITS 下,对大型与轻量级网络进行百万级训练时,可实现哪些性能提升?
- RQ4分布式训练是否能够缩小学术界与产业界在百万级人脸识别中的数据与计算差距?
- RQ5与公开数据集相比,WebFace42M 在具有挑战性的基准(IJB-C、NIST-FRVT)上的表现如何?
主要发现
- 在 IJB-C 上,WebFace42M 在标准 ResNet-100 配置下实现 TAR@FAR=1e-4 为 97.70%,使错误率相对于公开 SOTA 下降约 40%。
- 使用 WebFace4M(WebFace42M 的 10%)已在公开训练集如 MS1M 家族和 MegaFace2 上表现出色高于。
- WebFace42M 在 NIST-FRVT 的 430 个条目中排名第 3;这表明百万规模数据在时限约束基准中的竞争力。
- WebFace42M 提供了迄今为止最大的公开可得的清洗训练集,显著提升了 heavyweight 与 lightweight 模型的性能。
- 采用混合精度以及特征/中心并行的分布式训练实现近线性加速(如可达 32 个节点),且性能损失极小。
- 在 FRUITS 下,从轻量到重量级模型的一系列基线揭示了显著的差距和改进空间,尤其是在 FRUITS-100(轻量)和 FRUITS-1000(重量级)轨道。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。