[论文解读] What does it take to catch a Chinchilla? Verifying Rules on Large-Scale Neural Network Training via Compute Monitoring
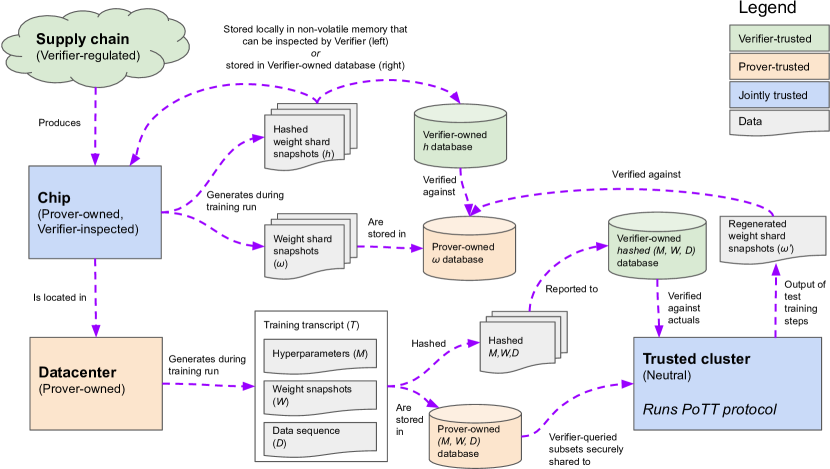
本文提出一个硬件-软件监控框架,通过在ML芯片上记录权重快照、转录本来源证明,以及供应链监控,实现在高概率下检测违反规则的训练运行,同时不暴露专有数据。
As advanced machine learning systems' capabilities begin to play a significant role in geopolitics and societal order, it may become imperative that (1) governments be able to enforce rules on the development of advanced ML systems within their borders, and (2) countries be able to verify each other's compliance with potential future international agreements on advanced ML development. This work analyzes one mechanism to achieve this, by monitoring the computing hardware used for large-scale NN training. The framework's primary goal is to provide governments high confidence that no actor uses large quantities of specialized ML chips to execute a training run in violation of agreed rules. At the same time, the system does not curtail the use of consumer computing devices, and maintains the privacy and confidentiality of ML practitioners' models, data, and hyperparameters. The system consists of interventions at three stages: (1) using on-chip firmware to occasionally save snapshots of the the neural network weights stored in device memory, in a form that an inspector could later retrieve; (2) saving sufficient information about each training run to prove to inspectors the details of the training run that had resulted in the snapshotted weights; and (3) monitoring the chip supply chain to ensure that no actor can avoid discovery by amassing a large quantity of un-tracked chips. The proposed design decomposes the ML training rule verification problem into a series of narrow technical challenges, including a new variant of the Proof-of-Learning problem [Jia et al. '21].
研究动机与目标
- 通过使政府能够验证训练规则,来推动对先进机器学习的治理。
- 提出一个覆盖芯片、数据中心和供应链的三层监控框架。
- 在实现高概率规则检测的同时,确保训练数据和模型的保密性。
- 评估部署此类验证系统的可行性、局限性与挑战。
提出的方法
- 引入由硬件支持固件证实的片上权重分片快照日志记录。
- 要求传输权重快照哈希及相应的训练转录本以证明来历(基于学习证明(Proof-of-Learning)启发的协议)。
- 实现供应链所有权验证,以防止未追踪的芯片被掩盖。
- 基于样本量和计算参数推导捕获违反规则的训练运行的概率保证。
- 提供定量表,估算在不同规模下对过去和未来模型所需的检查次数。
实验结果
研究问题
- RQ1验证者可以要求的最小可验证行动是什么,以高概率检测到对ML训练规则的违规?
- RQ2如何将芯片级日志、训练转录本和供应链监控整合起来,提供稳健的合规证明?
- RQ3为发现大规模违规训练运行所需的实际样本量和检查频率是多少?
- RQ4哪些规则(计算、数据属性、超参数、性能阈值)可以通过此监控方法执行?
- RQ5所提出框架的可扩展性和安全性局限有哪些?
主要发现
- 基于抽样的框架通过检查部分芯片并核对权重快照哈希与训练转录本,可以在高概率下检测违规训练运行。
- 本文给出定量估计,显示针对不同模型和芯片数量每年的所需样本量,体现了模型规模与可扩展性之间的关系。
- 权重分片快照和哈希来历信息使得回溯性验证成为可能,而不暴露专有数据或权重。
- 供应链监控对于防止未跟踪芯片掩盖大规模训练至关重要。
- 该方法主要可用于在专用加速器上的大规模训练,较老芯片和非中心化计算存在局限。
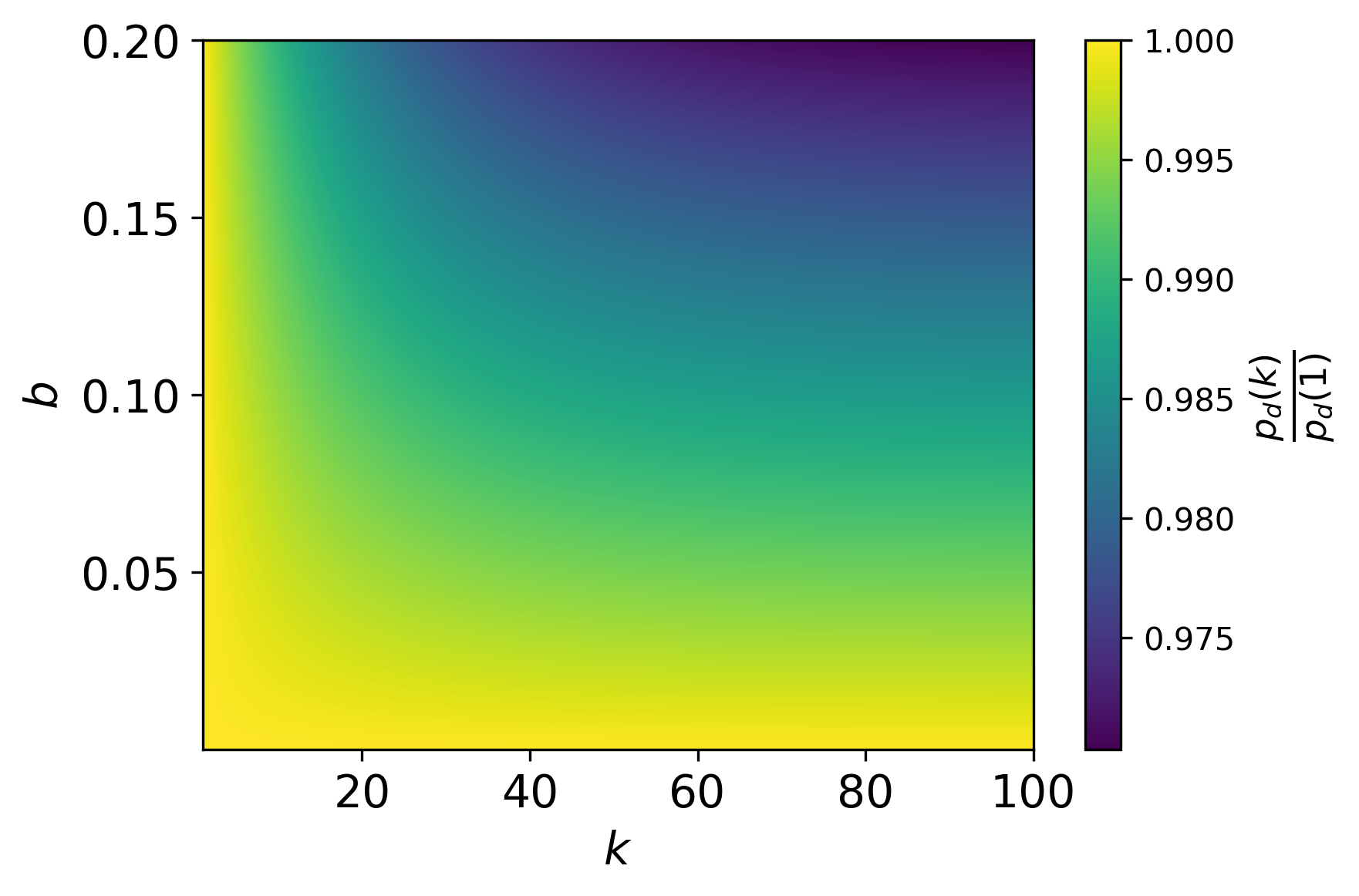
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。