[论文解读] What Makes Good Examples for Visual In-Context Learning?
本论文分析在上下文中的视觉示例选择如何对性能产生关键影响,并提出一个提示检索框架,包含无监督和有监督变体,用于自动为视觉上下文学习选择有益的提示。
Large-scale models trained on broad data have recently become the mainstream architecture in computer vision due to their strong generalization performance. In this paper, the main focus is on an emergent ability in large vision models, known as in-context learning, which allows inference on unseen tasks by conditioning on in-context examples (a.k.a.~prompt) without updating the model parameters. This concept has been well-known in natural language processing but has only been studied very recently for large vision models. We for the first time provide a comprehensive investigation on the impact of in-context examples in computer vision, and find that the performance is highly sensitive to the choice of in-context examples. To overcome the problem, we propose a prompt retrieval framework to automate the selection of in-context examples. Specifically, we present (1) an unsupervised prompt retrieval method based on nearest example search using an off-the-shelf model, and (2) a supervised prompt retrieval method, which trains a neural network to choose examples that directly maximize in-context learning performance. The results demonstrate that our methods can bring non-trivial improvements to visual in-context learning in comparison to the commonly-used random selection.
研究动机与目标
- 研究在上下文示例选择如何影响视觉上下文学习性能。
- 量化下游任务对视觉模型提示选择的敏感性。
- 开发自动提示检索方法,以提升提示质量,优于随机选择。
- 在分布移位和多种视觉任务下评估鲁棒性。
提出的方法
- 模型无关的视觉上下文学习设置,其中提示是一组图像-标签对,用于在不更新模型参数的情况下指导预测。
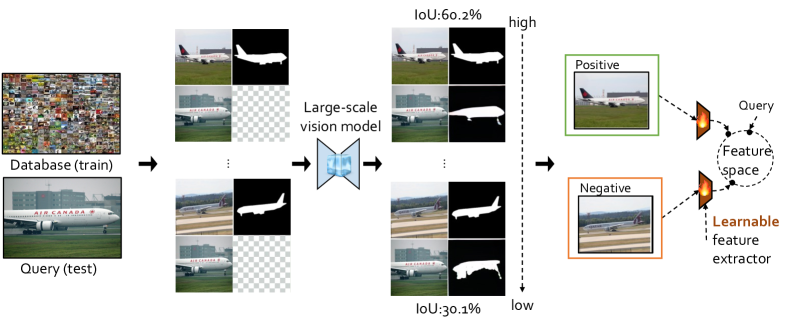
- 提出一个基于分数的提示检索框架 f_theta(x_n, x_q) 以为查询 x_q 选择最优提示。
- 通过固定的现成特征实现无监督提示检索(UnsupPR),采用最近邻搜索。
- 通过学习具有对比目标的特征提取器实现有监督提示检索(SupPR),以最大化上下文学习性能。
- 使用对比损失训练 SupPR,以基于前5个正/负性能集合拉拢/排斥提示。
- 使用三个下游任务(前景分割、单对象检测、图像着色)以及一个预训练的图像修复模型进行评估。
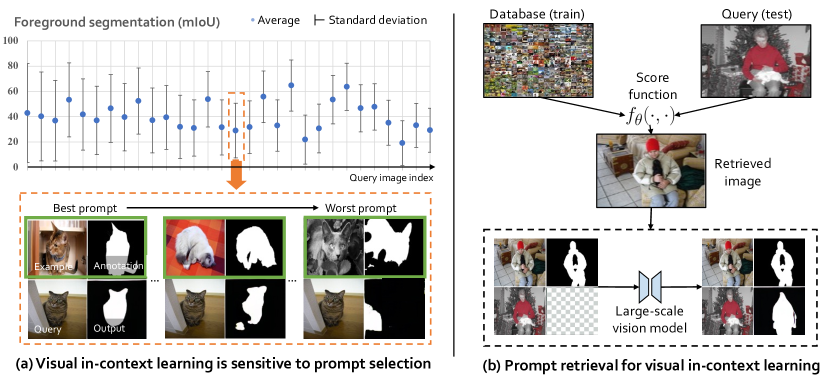
实验结果
研究问题
- RQ1在不同任务中,上下文示例的选择如何影响视觉上下文学习性能?
- RQ2自动提示检索是否能在随机提示选择之上提升性能?
- RQ3无监督和有监督的提示检索策略是否有效,哪一个效果更好?
- RQ4提示大小、主干网络和检索集合大小如何影响结果以及对分布移位的鲁棒性?
主要发现
- 在前景分割和对象检测上,提示检索明显优于随机提示选择(分别获得≥6%的mIoU提升和约1%的提升)。
- 有监督的提示检索方法(SupPR)在所有任务中始终优于无监督变体(UnsupPR)和随机基线。
- 无论背骨网络(CLIP、EVA、ViT)如何,提示检索的性能提升都存在,对骨干的敏感性很小。
- 与分布移位(从 Pascal 到 MSCOCO)的鲁棒性方面,SupPR 显示优于 UnsupPR 或 Random,尽管在移位下整体增益小于同分布内的增益。
- 增加上下文示例数量通常会提升所有方法的性能,而顺序在选择高质量示例时影响很小。
- SupPR 倾向于选择在语义和空间上更接近查询的提示,提示语义相似性与上下文相似性的平衡是有益的。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。