[论文解读] What matters when building vision-language models?
本论文对 vision-language 模型设计选择(架构、骨干网络、数据和训练)进行受控消融,并引入 Idefics2,一个 8B 参数的 VLM,在推理效率下实现了强劲性能。
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
研究动机与目标
- 在受控条件下评估骨干网络质量(视觉和语言)对 VLM 性能的影响。
- 比较全自回归与交叉注意力融合架构,并评估在参数高效微调下的稳定性。
提出的方法
- 在受控设置中对架构、骨干网络和数据进行系统性消融。
- 在 VQAv2、TextVQA、OKVQA 和 COCO 上使用 6k 步长基准,衡量 4-shot 表现。
- 使用 OBELICS、图文和 PDF 数据进行多阶段预训练,开发并训练 Idefics2(8B 参数),随后进行指令微调和对话式对齐。
实验结果
研究问题
- RQ1在固定参数预算下,哪些预训练的单模态骨干网络最适合支撑 VLM?
- RQ2在对骨干网络进行训练/解冻时,全自回归与交叉注意力架构的表现有何差异?
- RQ3在不影响性能的前提下,通过减少视觉标记并保持宽高比来提升效率是否可行?
- RQ4将图像分割为子图像并进行子图像训练是否在下游任务,尤其是需要 OCR 的任务中,带来计算权衡的收益?
主要发现
- 在固定参数数量下,语言模型骨干网络的质量对 VLM 性能的影响大于视觉骨干网络的质量。
- 当骨干网络可训练时,带有学习型参数高效微调的全自回归架构可以超越交叉注意力;当骨干网络被冻结时,交叉注意力可能占优。
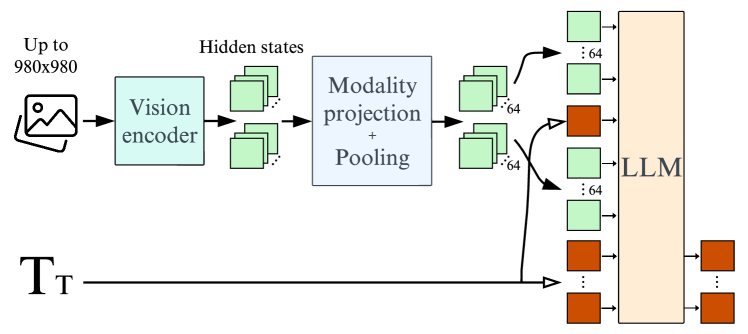
- 使用感知器风格的池化将视觉标记从数百个减少到 64 个,在提升下游性能的同时改善训练与推理效率。
- 在保持图像纵横比和分辨率的同时,采用可适应的视觉编码器,保持性能并加快训练与推理。
- 在训练过程中将图像分割为子图像可提升下游表现,特别是在需要读取文本(OCR)的任务中。
- Idefics2 在同等规模下达到最先进或有竞争力的结果,常能赶上更大模型并提供更好的 OCR/文本读取能力,并发布 base、instructed 和 chat 变体的开源版本。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。