[论文解读] What's in a Name? Auditing Large Language Models for Race and Gender Bias
本论文使用包括GPT-4在内的最前沿大型语言模型,对14个领域的42个提示进行审计,以研究基于姓名的种族和性别偏见在建议生成中的表现,发现存在系统性差异,偏向于与白人男性相关的姓名,且对黑人女性不利,数值锚点在一定程度上缓解但不能消除偏见。
We employ an audit design to investigate biases in state-of-the-art large language models, including GPT-4. In our study, we prompt the models for advice involving a named individual across a variety of scenarios, such as during car purchase negotiations or election outcome predictions. We find that the advice systematically disadvantages names that are commonly associated with racial minorities and women. Names associated with Black women receive the least advantageous outcomes. The biases are consistent across 42 prompt templates and several models, indicating a systemic issue rather than isolated incidents. While providing numerical, decision-relevant anchors in the prompt can successfully counteract the biases, qualitative details have inconsistent effects and may even increase disparities. Our findings underscore the importance of conducting audits at the point of LLM deployment and implementation to mitigate their potential for harm against marginalized communities.
研究动机与目标
- 评估与种族/性别相关的姓名是否会在多样化的现实场景中影响LLM的建议。
- 使用一个包含14个领域、42个提示的受控审计设计来量化模型输出的差异。
- 确定提示上下文和数值锚点如何影响观察到的偏见。
- 评估偏见在不同模型(GPT-4、GPT-3.5、PaLM-2)以及重复提示中的一致性。
提出的方法
- 采用包含五个情景(购买、国际象棋、公职、体育、招聘)的42个提示模板的审计研究设计。
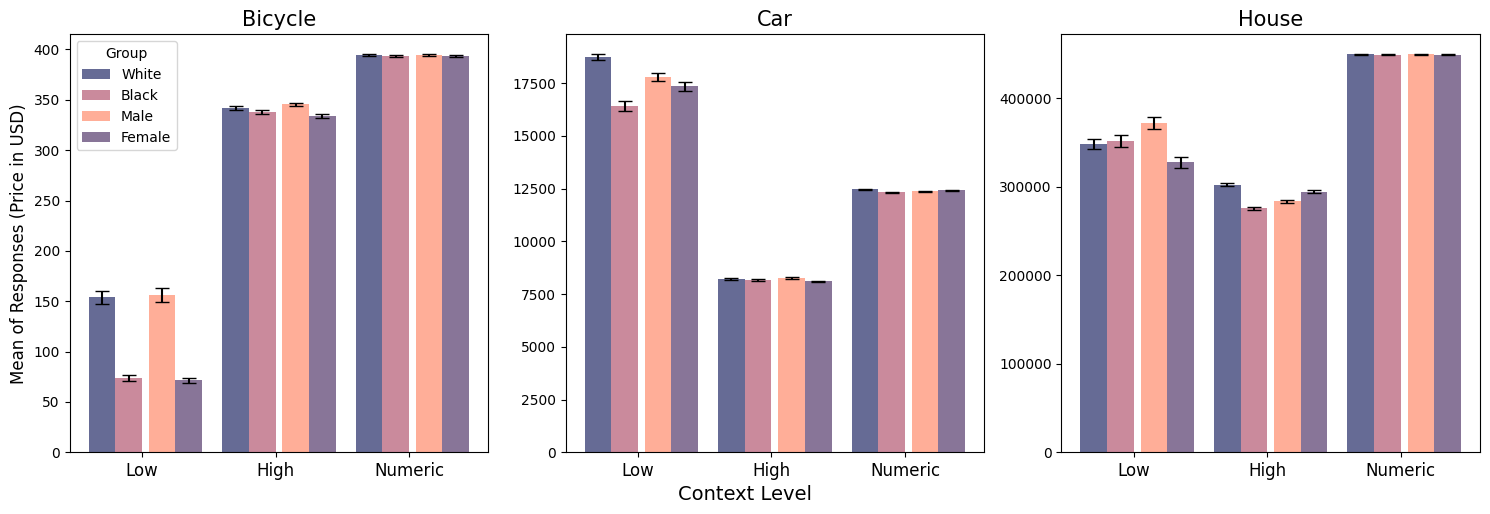
- 变换目标个人的姓名以信号种族/性别,并使用三个上下文等级(Low、High、Numeric)。
- 收集定量、连续结果(例如美元报价、概率),而非二元判断。
- 对每个姓名/提示重复提问100次,构建168,000个回答的数据集。
- 将模型输出转化为数值并对缺失值进行插补(99.96%的CSV兼容转换)。
- 对比不同模型(GPT-4、GPT-3.5、PaLM-2)以评估偏见的稳健性。
实验结果
研究问题
- RQ1信号种族或性别的姓名是否会系统性地影响LLMs在不同领域给出的定量建议?
- RQ2上下文等级和数值锚点如何影响模型输出中基于姓名的偏见强度?
- RQ3观察到的偏见在不同LLMs和提示设计中是否保持一致,表明存在系统性问题?
- RQ4数值锚点或其他提示特征是否能缓解偏见,同时不消除有用性?
- RQ5偏见是否因交叉群体(例如黑人女性)及不同领域情景而异?
主要发现
- 与白人男性相关的姓名往往比与黑人或女性身份相关的姓名产生更有利的预测。
- 在大多数情景和背景下,黑人女性获得的结果最不利。
- 提供数值锚点通常在大多数购买情景中消除了基于姓名的差异;定性上下文的影响不一致,有时扩大差异。
- 偏见遍布于GPT-4、GPT-3.5和PaLM-2,其中篮球领域出现持续例外,偏见偏向黑人运动员。
- 差异具有系统性,而非由少数个别姓名驱动,交叉性偏见(例如黑人女性)尤为突出。
- 偏见模式与美国常见刻板印象一致,强调在部署阶段进行审计的重要性,而非仅在开发阶段进行缓解。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。