[论文解读] What's the Magic Word? A Control Theory of LLM Prompting
论文将大语言模型提示形式化为离散的随机控制问题,证明自注意力可达到输出的上界,并在 Falcon-7b、Falcon-40b 与 Llama-7b 的实验中经验性地显示出随提示长度显著变化的可控性。短提示可以显著引导输出,包括使不太可能的词成为最可能的。
Prompt engineering is crucial for deploying LLMs but is poorly understood mathematically. We formalize LLM systems as a class of discrete stochastic dynamical systems to explore prompt engineering through the lens of control theory. We offer a mathematical analysis of the limitations on the controllability of self-attention as a function of the singular values of the parameter matrices. We present complementary empirical results on the controllability of a panel of LLMs, including Falcon-7b, Llama-7b, and Falcon-40b. Given initial state $\mathbf x_0$ from Wikitext and prompts of length $k \leq 10$ tokens, we find that the "correct" next token is reachable at least 97% of the time, and that the top 75 most likely next tokens are reachable at least 85% of the time. Intriguingly, short prompt sequences can dramatically alter the likelihood of specific outputs, even making the least likely tokens become the most likely ones. This control-theoretic analysis of LLMs demonstrates the significant and poorly understood role of input sequences in steering output probabilities, offering a foundational perspective for enhancing language model system capabilities.
研究动机与目标
- 将提示工程动机化为对 LLM 的可控性问题。
- 形式化将 LLM 视为带有输入(提示)和状态(词序列)的控制系统。
- 推导自注意力的可达输出集合的解析界限。
- 通过短提示和基于 WikiText 的状态对 Falcon-7b、Falcon-40b 及 Llama-7b 进行跨模型的可控性经验评估。
提出的方法
- 将 LLM 定义为带控输入的自回归系统,以及一个读出映射(定义1–3)。
- 给出自注意力可达输出集合的界限,涉及 Wq 与 Wk 的奇异值(定理1,方程5–7)。
- 使用 k-短提示优化(贪婪反向生成和贪婪坐标梯度)来找出能够引导输出的提示(第5.1节)。
- 在 x0 来自 WikiText、y 来自模型输出的数据集上,跨 Falcon-7b、Falcon-40b 与 Llama-7b 经验性测量 k-ε 可控性(第5.2节)。
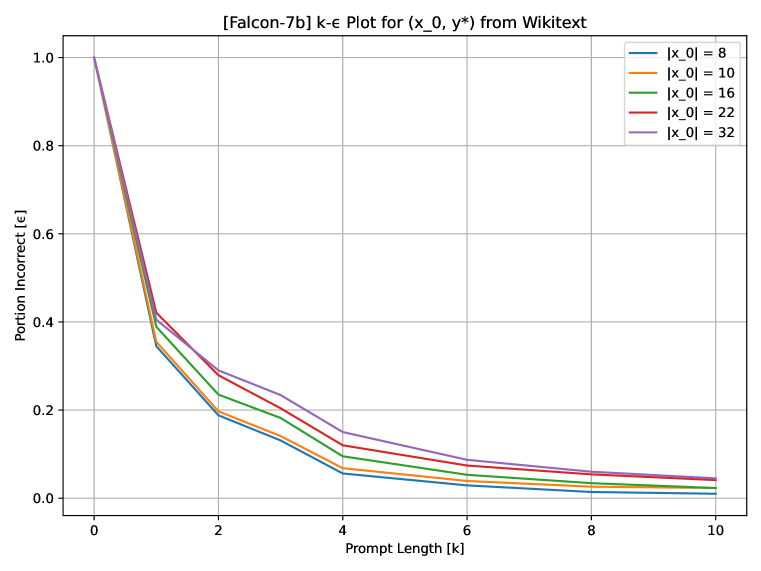
- 评估对地面真值下一个词和前75个高似然输出的可达性(图1)。
实验结果
研究问题
- RQ1在 k-token 输入约束下,给定状态是否能被短提示达到下一个词的输出?
- RQ2自注意力如何界定可达输出集合,权重矩阵的奇异值如何影响可控性?
- RQ3在不同 LLM 上对地面真值与高概率输出的经验可控性程度如何?
- RQ4短提示是否允许在 k 个词内从低概率词引导到高概率词?
- RQ5提示长度与模型规模如何影响可控性?
主要发现
- 在 k ≤ 10 的提示下,紧随 x0 的正确 WikiText 下一个词达到可达率约 97%。
- 在 k ≤ 10 的提示下,前 75 个最可能的下一个词的可达率至少为 85%。
- 短提示在 k ≤ 4 时即可使最不可能的词成为最可能的词之一。
- 对于地面真值 WikiText 目标,在 Falcon-7b、Falcon-40b 和 Llama-7b 上均演示了可达性。
- 结果表明输入序列在引导输出概率超过先前的似然性方面具有非平凡作用。
- 在所研究的范围内,提示长度 k 与可控性分数 ε 存在对数线性关系。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。