[论文解读] What Should Data Science Education Do with Large Language Models?
本文主张大型语言模型(LLMs)通过将数据科学家转向类似产品管理的角色来改变数据科学教育,并提出将LLMs整合到课程中作为教学工具,同时解决伦理、抄袭和创造性思维等问题。
The rapid advances of large language models (LLMs), such as ChatGPT, are revolutionizing data science and statistics. These state-of-the-art tools can streamline complex processes. As a result, it reshapes the role of data scientists. We argue that LLMs are transforming the responsibilities of data scientists, shifting their focus from hands-on coding, data-wrangling and conducting standard analyses to assessing and managing analyses performed by these automated AIs. This evolution of roles is reminiscent of the transition from a software engineer to a product manager. We illustrate this transition with concrete data science case studies using LLMs in this paper. These developments necessitate a meaningful evolution in data science education. Pedagogy must now place greater emphasis on cultivating diverse skillsets among students, such as LLM-informed creativity, critical thinking, AI-guided programming. LLMs can also play a significant role in the classroom as interactive teaching and learning tools, contributing to personalized education. This paper discusses the opportunities, resources and open challenges for each of these directions. As with any transformative technology, integrating LLMs into education calls for careful consideration. While LLMs can perform repetitive tasks efficiently, it's crucial to remember that their role is to supplement human intelligence and creativity, not to replace it. Therefore, the new era of data science education should balance the benefits of LLMs while fostering complementary human expertise and innovations. In conclusion, the rise of LLMs heralds a transformative period for data science and its education. This paper seeks to shed light on the emerging trends, potential opportunities, and challenges accompanying this paradigm shift, hoping to spark further discourse and investigation into this exciting, uncharted territory.
研究动机与目标
- 解释 LLMs 如何改变数据科学流程及专业角色。
- 提出将 LLMs 融入课程与教学实践的教育策略。
- 讨论在数据科学教育中实施 LLMs 的机会、资源与挑战。
- 在 LLM 支持的教育中解决伦理、抄袭与评估方面的考量。
提出的方法
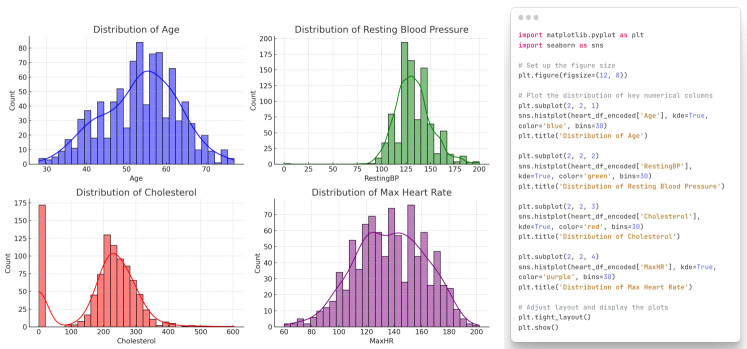
- 对 LLM 能力(数据清洗、探索、建模、解释、报告)的评述,结合使用 ChatGPT 插件的心脏病数据集案例研究。
- 展示 LLMs 解决考试式问题及通过代码解释器实现数据科学流程自动化。
- 讨论课程设计示例,包括动态课程和测验设计,在 LLMs 的帮助下。
- 评估教学助手和 2 Sigma 问题对个性化辅导的影响。
实验结果
研究问题
- RQ1LLMs 如何重塑数据科学流程以及数据科学家的角色?
- RQ2在 LLM 增强的数据科学时代,应强调哪些教育内容与方法?
- RQ3如何将 LLMs 融入数据科学教学,以提升学习效果并降低抄袭等风险?
- RQ4在数据科学教育中采用 LLMs 的伦理、实践与资源相关挑战有哪些?
主要发现
- 在案例研究中,LLMs 能自动化数据科学流程的阶段,从数据清洗到报告撰写。
- 带有代码插件的 ChatGPT 能在最少提示下执行数据分析任务,体现潜在的工作流变革。
- 考试与练习显示 LLMs 在统计问题上具高性能,表明对学生评估的风险。
- 使用 LLMs 的课程设计、个性化辅导和自动化教育系统带来机遇,但需对抄袭和偏见等进行审慎防护。
- 这一转变类似于从软件工程向产品管理的转变,强调规划、协调和监督。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。