[论文解读] Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
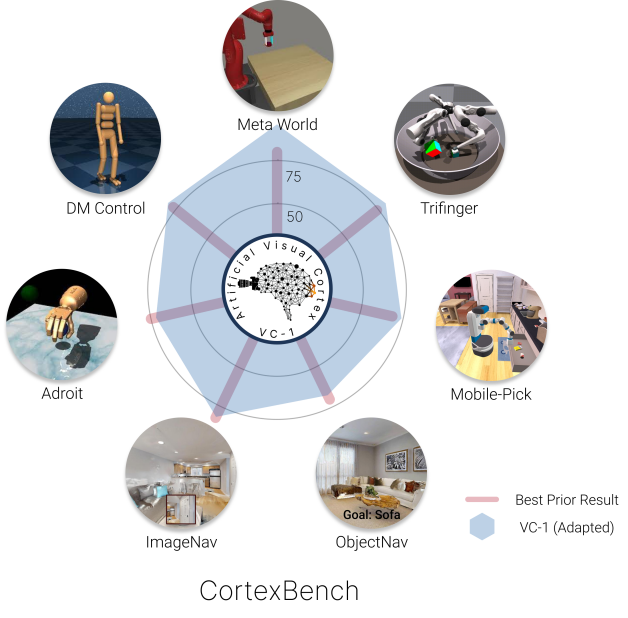
本工作提出 CortexBench,这是对嵌入式 AI 的预训练视觉表示的最大规模评估,未出现普遍冠军;VC-1 (adapted) 在平均水平上最强,且对任务进行适应的 VC-1 能匹配或超过 CortexBench 基准上的最新方法。
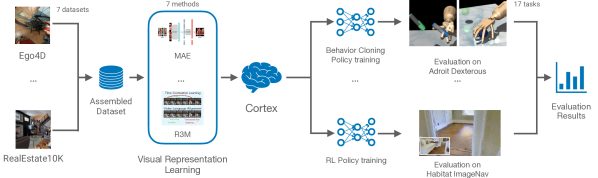
We present the largest and most comprehensive empirical study of pre-trained visual representations (PVRs) or visual 'foundation models' for Embodied AI. First, we curate CortexBench, consisting of 17 different tasks spanning locomotion, navigation, dexterous, and mobile manipulation. Next, we systematically evaluate existing PVRs and find that none are universally dominant. To study the effect of pre-training data size and diversity, we combine over 4,000 hours of egocentric videos from 7 different sources (over 4.3M images) and ImageNet to train different-sized vision transformers using Masked Auto-Encoding (MAE) on slices of this data. Contrary to inferences from prior work, we find that scaling dataset size and diversity does not improve performance universally (but does so on average). Our largest model, named VC-1, outperforms all prior PVRs on average but does not universally dominate either. Next, we show that task- or domain-specific adaptation of VC-1 leads to substantial gains, with VC-1 (adapted) achieving competitive or superior performance than the best known results on all of the benchmarks in CortexBench. Finally, we present real-world hardware experiments, in which VC-1 and VC-1 (adapted) outperform the strongest pre-existing PVR. Overall, this paper presents no new techniques but a rigorous systematic evaluation, a broad set of findings about PVRs (that in some cases, refute those made in narrow domains in prior work), and open-sourced code and models (that required over 10,000 GPU-hours to train) for the benefit of the research community.
研究动机与目标
- Motivate the search for an artificial visual cortex by evaluating a broad set of pre-trained visual representations (PVRs) on diverse embodied AI tasks.
- Create CortexBench to benchmark PVRs across locomotion, navigation, and manipulation tasks with varied embodiments.
- Assess whether scaling data/model size yields universal gains across tasks.
- Investigate adaptation strategies to bridge domain gaps between pre-training data and embodied tasks.
- Open-source datasets, models, and code to accelerate community benchmarking.
提出的方法
- Curate CortexBench with 17 tasks from 7 embodied AI benchmarks spanning navigation and manipulation.
- Evaluate frozen PVR backbones (CLIP, MVP, VIP, R3M) to assess universal performance.
- Train ViT-B/ViT-L backbones on four pre-training datasets (Ego4D-derived and ImageNet) using MAE pre-training.
- Measure performance on CortexBench using mean success and mean rank as evaluation metrics.
- Compare VC-1 (largest model trained on all data) against existing PVRs to establish relative strength.
- Demonstrate adaptation of VC-1 via end-to-end fine-tuning and MAE-based adaptation to improve task-specific performance.
实验结果
研究问题
- RQ1Do existing pre-trained visual representations dominate across a broad set of Embodied AI tasks?
- RQ2How does scaling model size and dataset size/diversity affect performance on CortexBench tasks?
- RQ3Can task-specific adaptation of a strong PVR close the gap to or surpass task-specific state-of-the-art results?
- RQ4What is the impact of adapting PVRs through end-to-end fine-tuning versus MAE adaptation on downstream tasks?
主要发现
- No single pre-trained visual representation dominates all CortexBench tasks.
- The largest model VC-1 (ViT-L trained on Ego4D+MNI) achieves best average rank and higher mean success than many baselines, but is not best for every task.
- Scaling dataset size and diversity improves performance on average but does not universally improve all tasks.
- Task-specific adaptation of VC-1 (VC-1 adapted) yields competitive or superior results across CortexBench benchmarks, often surpassing prior state-of-the-art.
- VC-1 and VC-1 adapted outperform leading pre-existing PVRs in real hardware experiments on several tasks.
- End-to-end fine-tuning of VC-1 boosts performance in large-scale IL/RL tasks but can hurt performance in few-shot imitation domains due to overfitting.
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。