[论文解读] WhiteFox: White-Box Compiler Fuzzing Empowered by Large Language Models
WhiteFox 引入了一种白盒编译器模糊测试器,它使用 LLMs 分析优化代码并生成测试输入,在多个编译器上实现更高的优化覆盖并发现大量漏洞。
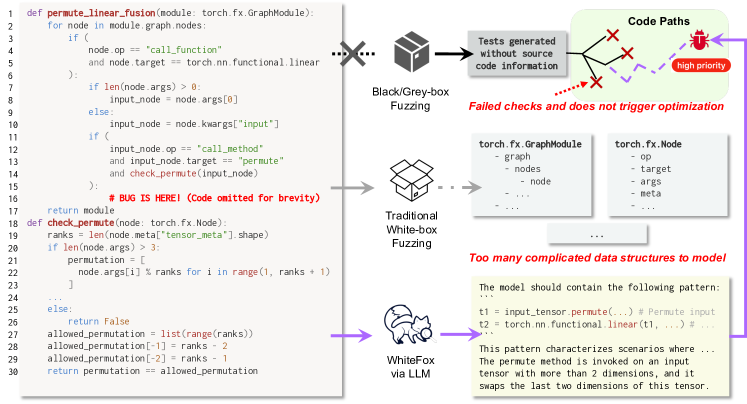
Compiler correctness is crucial, as miscompilation can falsify program behaviors, leading to serious consequences. Fuzzing has been studied to uncover compiler defects. However, compiler fuzzing remains challenging: Existing arts focus on black- and grey-box fuzzing, which generates tests without sufficient understanding of internal compiler behaviors. Meanwhile, traditional white-box techniques, like symbolic execution, are computationally inapplicable to the giant codebase of compilers. Recent advances demonstrate that Large Language Models (LLMs) excel in code generation/understanding tasks. Nonetheless, guiding LLMs with compiler source-code information remains a missing piece of research in compiler testing. To this end, we propose WhiteFox, the first white-box compiler fuzzer using LLMs with source-code information to test compiler optimization, with a spotlight on detecting deep logic bugs in the deep learning (DL) compilers. WhiteFox adopts a multi-agent framework: an LLM-based analysis agent examines the low-level optimization source code and produces requirements on the high-level test programs that can trigger the optimization; an LLM-based generation agent produces test programs based on the summarized requirements. Additionally, optimization-triggering tests are used as feedback to enhance the generation on the fly. Our evaluation on the three most popular DL compilers (i.e., PyTorch Inductor, TensorFlow-XLA, and TensorFlow Lite) shows WhiteFox can generate high-quality test programs to exercise deep optimizations, practicing up to 8X more than state-of-the-art fuzzers. WhiteFox has found 101 bugs for the DL compilers, with 92 confirmed as previously unknown and 70 fixed. WhiteFox has been acknowledged by the PyTorch team and is being incorporated into its development workflow. Beyond DL compilers, WhiteFox can also be adapted for compilers in different domains.
研究动机与目标
- 推动对可靠的编译器优化以及可扩展的白盒模糊测试的需求,超越传统的符号推理或覆盖驱动方法。
- 提出一个双 LLM 框架,将优化实现转换为高层次的测试输入。
- 开发一个反馈回路,使用触发优化的测试来迭代改进测试输入。
- 在多个编译器上评估 WhiteFox,以评估优化覆盖率和漏洞发现能力。
提出的方法
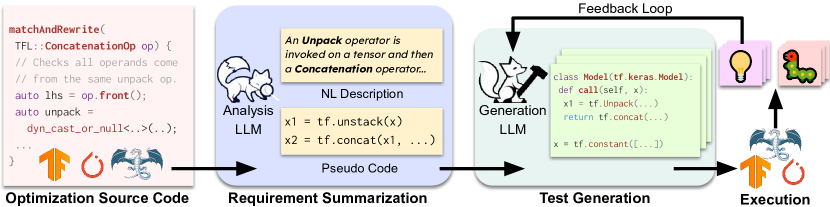
- 利用分析型 LLM 将低级优化代码总结为混合自然语言和伪代码格式的高级触发需求。
- 使用生成型 LLM 来生成满足所述概要要求的测试程序(例如 PyTorch 模型)。
- 实现一个反馈回路,将触发优化的测试作为少量示例添加,以改进未来的生成。
- 对编译器进行插桩,以在触发优化时检测并将崩溃或结果不一致识别为测试准则。
- 应用基于 Thompson 采样的多臂赌博机来选择有效的触发示例,以在测试生成中平衡探索与利用。
实验结果
研究问题
- RQ1LLMs 能否将低级优化实现翻译成能够有效触发编译器优化的高级输入需求?
- RQ2在跨越多种编译器的情况下,由 LLM 指导的测试输入是否比现有模糊测试工具产生更深的优化覆盖?
- RQ3反馈回路和示例选择策略在改进后续测试生成方面有多有效?
主要发现
- 在实验中,WhiteFox 在被执行的优化数量上实现的覆盖率最多达到 state-of-the-art fuzzers 的 8 倍。
- 该框架在测试的编译器中发现了 96 个漏洞,其中 80 个此前未知,51 个已被修复。
- WhiteFox 在四个受测对象(包括三个 DL 编译器和 LLVM)上显示出更高的优化覆盖率。
- 自然语言和伪代码摘要的结合提高了触发优化的需求提取。
- 使用触发测试作为少量-shot 示例和 Thompson Sampling 的反馈回路能够改进后续测试生成。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。