[论文解读] Why Linguistics Will Thrive in the 21st Century: A Reply to Piantadosi (2023)
本论文批评 Piantadosi 的说法,即语言模型推翻乔姆斯基,主张:(1) 在核心学习理论极限下,难以在有限数据上实现无约束学习;(2) 大型语言模型不是语言的科学理论;(3)多重实现性意味着 AI 模拟并不等同于人类认知;生成语言学在本质上仍然不可或缺。
We present a critical assessment of Piantadosi's (2023) claim that "Modern language models refute Chomsky's approach to language," focusing on four main points. First, despite the impressive performance and utility of large language models (LLMs), humans achieve their capacity for language after exposure to several orders of magnitude less data. The fact that young children become competent, fluent speakers of their native languages with relatively little exposure to them is the central mystery of language learning to which Chomsky initially drew attention, and LLMs currently show little promise of solving this mystery. Second, what can the artificial reveal about the natural? Put simply, the implications of LLMs for our understanding of the cognitive structures and mechanisms underlying language and its acquisition are like the implications of airplanes for understanding how birds fly. Third, LLMs cannot constitute scientific theories of language for several reasons, not least of which is that scientific theories must provide interpretable explanations, not just predictions. This leads to our final point: to even determine whether the linguistic and cognitive capabilities of LLMs rival those of humans requires explicating what humans' capacities actually are. In other words, it requires a separate theory of language and cognition; generative linguistics provides precisely such a theory. As such, we conclude that generative linguistics as a scientific discipline will remain indispensable throughout the 21st century and beyond.
研究动机与目标
- 评估现代语言模型是否推翻 native-language learning constraints 与 Chomsky 的观点。
- 论证在计算学习理论结果下,来自少量数据的无约束学习不可行。
- 评估 LLMs 能否作为语言与认知的科学理论的主张。
- 强调人类语言能力需要一个独立的语言与认知理论。
- 主张生成语言学在二十一世纪仍然不可或缺。
提出的方法
- 批判性分析 Piantadosi(2023)关于 LLMs 与语言学习的主张。
- 借助计算学习理论(CLT)说明概念族、数据呈现和计算资源之间的权衡。
- 解释 LLMs 的经验结果如何受到评估数据中的偏差和潜在捷径的影响。
- 以测试集(如 BLiMP)为例,说明表现可能反映捷径而非真实语法知识。
- 讨论多重实现性,以区分表面行为相似与潜在认知机制的不同。
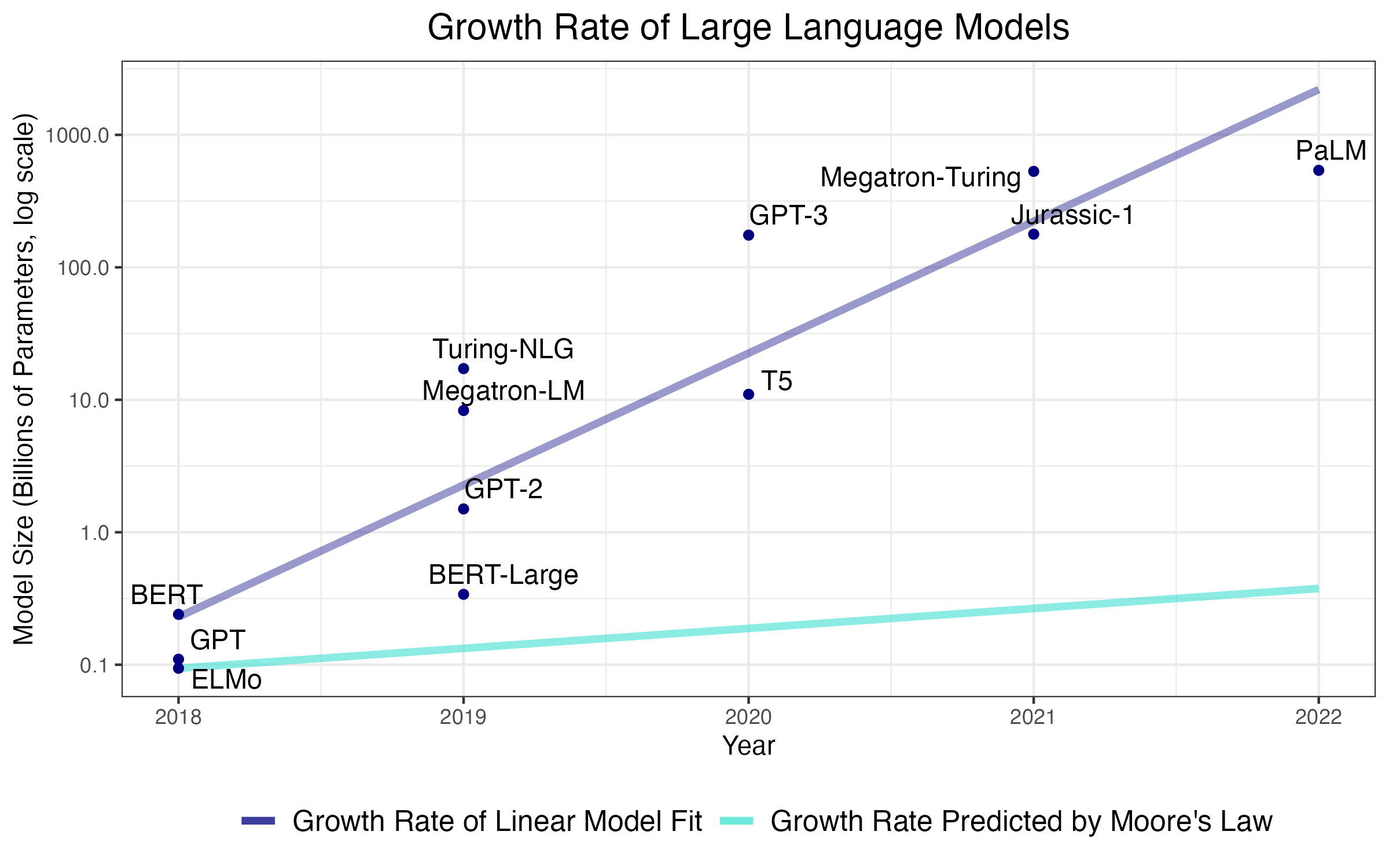
实验结果
研究问题
- RQ1LLMs 是否在与人类暴露量相当的数据规模上展示了无约束学习?
- RQ2LLMs 是可靠的语言与认知科学理论,还是仅预测输出?
- RQ3是否存在能够提供可解释解释的独立语言与认知理论(如生成语言学)?
- RQ4有哪些证据可以 claim LLMs 编码类似人类的语言知识,而非利用捷径?
- RQ5在计算学习理论的框架下,如何解读“少量数据”学习的主张?
主要发现
- 在符合人类语言暴露规模的可观数据下,基于学习基本规律的无约束学习在理论上不太可能。
- 大型语言模型依赖非平凡的结构先验与庞大数据,挑战它们从少量数据中像人类一样学习的想法。
- 用于句法的评估基准往往容许捷径,这些捷径并不揭示真实的语法知识,因而对 LLMs 是否具有人类般语言学能力的结论值得怀疑。
- 多重实现性表明相同的表现并不意味着 AI 与人类认知在底层机制上相同。
- 表明需要独立的语言与认知理论来解释 AI 能力,支持生成语言学在未来仍扮演重要角色。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。