[论文解读] Why think step by step? Reasoning emerges from the locality of experience
本文表明,当训练数据具有局部结构时,链式思维推理有助于语言模型,通过串联局部依赖实现高效推断;在完全观测或非局部数据下,推理几乎没有优势。
Humans have a powerful and mysterious capacity to reason. Working through a set of mental steps enables us to make inferences we would not be capable of making directly even though we get no additional data from the world. Similarly, when large language models generate intermediate steps (a chain of thought) before answering a question, they often produce better answers than they would directly. We investigate why and how chain-of-thought reasoning is useful in language models, testing the hypothesis that reasoning is effective when training data consists of overlapping local clusters of variables that influence each other strongly. These training conditions enable the chaining of accurate local inferences to estimate relationships between variables that were not seen together in training. We prove that there will exist a "reasoning gap", where reasoning through intermediate variables reduces bias, for the simple case of an autoregressive density estimator trained on local samples from a chain-structured probabilistic model. We then test our hypothesis experimentally in more complex models, training an autoregressive language model on samples from Bayes nets but only including a subset of variables in each sample. We test language models' ability to match conditional probabilities with and without intermediate reasoning steps, finding that intermediate steps are only helpful when the training data is locally structured with respect to dependencies between variables. The combination of locally structured observations and reasoning is much more data-efficient than training on all variables. Our results illustrate how the effectiveness of reasoning step by step is rooted in the local statistical structure of the training data.
研究动机与目标
- 推导并形式化为何通过中间变量进行推理可以改善语言模型的推断。
- 形式化基于贝叶斯网的框架用于具有局部结构观测的条件推断。
- 证明链式结构模型中推理的理论偏差减少差距。
- 在具有局部结构的合成贝叶斯网数据上,实证测试中间推理何时有帮助。
提出的方法
- 形式化产生局部变量邻域的观测分布。
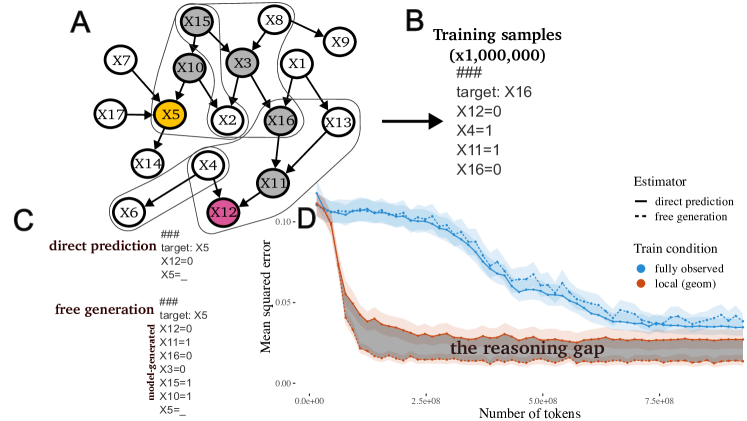
- 推导三种估计量:直接预测、搭 scaffold 的生成、以及对条件概率的自由生成。
- 证明在链式结构中,通过中间变量进行推理可降低非相邻变量对的偏差,从而产生“推理差距”。
- 在具有局部结构的合成贝叶斯网数据上训练自回归变换器,并评估未见对的条件概率。
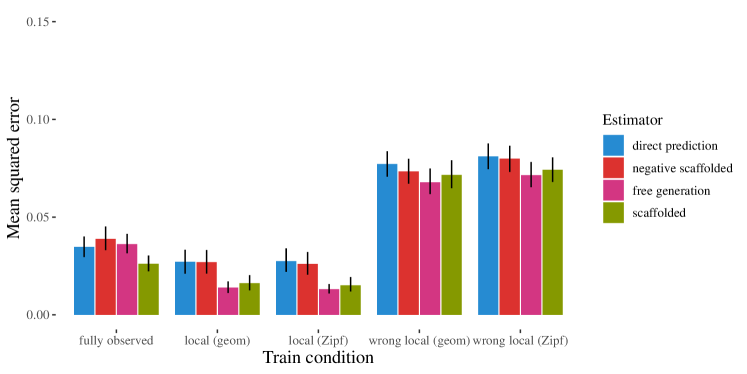
- 在局部结构、完全观测和错误设 locality 设置下,使用均方误差(MSE)比较估计量。
- 分析数据效率以及何时推理是多余或有害。
实验结果
研究问题
- RQ1在何种训练数据的局部性条件下,中间推理步骤会降低条件推断中的偏差?
- RQ2在局部结构下,自生成的中间推理是否帮助自回归模型比直接预测更接近真实条件概率?
- RQ3与在完全观测数据上学习相比,基于推理的推断的数据效率如何?
- RQ4何时推理不再有帮助或会降低性能?
- RQ5哪些因素(如局部性强度、变量之间距离等)会调节链式思维推理的有用性?
主要发现
- 当训练数据具有强局部结构时,通过中间变量进行推理可降低非相邻变量对的偏差。
- 在局部结构训练数据下,free generation 与 scaffolded generation 均优于直接预测。
- 在数据完全观测或局部性结构不正确时,推理几乎没有优势。
- 局部结构数据加上链式思维推理能提高数据效率,在较少训练数据下就接近真实的条件概率。
- 直接预测在观测变量经常同时出现时即可达到接近真实概率的水平,此时推理的需求减小。
- 重新采样推理链(多次蒙特卡洛采样)有助于降低估计方差。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。