[论文解读] xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval
xCodeEval 是最大的可执行多语言多任务基准,用于代码,涵盖 7.5K 道题目和 17 种语言,具备 7 个任务和一个基于执行的评估引擎 ExecEval。它允许对 LLM 的代码理解、生成、翻译和检索进行跨语言、跨任务、以及执行级别的评估。
Recently, pre-trained large language models (LLMs) have shown impressive abilities in generating codes from natural language descriptions, repairing buggy codes, translating codes between languages, and retrieving relevant code segments. However, the evaluation of these models has often been performed in a scattered way on only one or two specific tasks, in a few languages, at a partial granularity (e.g., function) level, and in many cases without proper training data. Even more concerning is that in most cases the evaluation of generated codes has been done in terms of mere lexical overlap with a reference code rather than actual execution. We introduce xCodeEval, the largest executable multilingual multitask benchmark to date consisting of $25$M document-level coding examples ($16.5$B tokens) from about $7.5$K unique problems covering up to $11$ programming languages with execution-level parallelism. It features a total of $7$ tasks involving code understanding, generation, translation and retrieval. xCodeEval adopts an execution-based evaluation and offers a multilingual code execution engine, ExecEval that supports unit test based execution in all the $11$ languages. To address the challenge of balancing the distributions of text-code samples over multiple attributes in validation/test sets, we propose a novel data splitting and a data selection schema based on the geometric mean and graph-theoretic principle. Our experiments with OpenAI's LLMs (zero-shot) and open-LLMs (zero-shot and fine-tuned) on the tasks and languages demonstrate **xCodeEval** to be quite challenging as per the current advancements in language models.
研究动机与目标
- 使用执行为基础的框架评估多语言程序理解、生成、翻译和检索。
- 提供覆盖多种编程语言和题目难度的大规模、多样化基准。
- 通过新颖的数据分割策略和执行引擎实现公平评估,执行引擎在多语言间运行单元测试。
提出的方法
- 从 Codeforces 构建一个包含 25M 样本、覆盖多达 17 种语言的 7.5K 道题目的数据集。
- 开发 ExecEval,一个安全、分布式执行引擎,支持 11 种语言的 44 个编译器/解释器用于基于单元测试的评估。
- 定义 7 个任务(2 个分类、3 个生成、2 个检索),采用执行为基础的评估。
- 使用基于几何平均数和循环问题的新颖数据拆分与样本选择策略,以在题目和标签之间平衡验证/测试分布。
- 在基准上评估 OpenAI 和开源 LLMs,以衡量当前能力并发现差距。
- 提供训练数据和评估资源(数据集、GitHub/Hub、文档)。
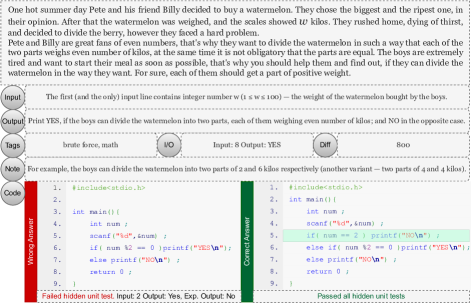
实验结果
研究问题
- RQ1在使用执行单元测试评估时,多语言 LLM 在代码理解、生成、翻译和检索方面的表现如何?
- RQ2在 17 种语言中,可执行代码任务的跨语言迁移和零-shot 能力如何?
- RQ3不同题目难度和语言资源如何影响程序合成、修复和翻译的表现?
- RQ4所提出的数据分割和采样策略是否能在多属性间产生平衡、具有代表性的验证/测试集?
- RQ5关于当前 LLM 的可执行代码能力和跨语言推理,可以得出哪些见解?
主要发现
- xCodeEval 对最先进的 LLMs 来说具有挑战性,包括跨任务与跨语言的零-shot 和微调模型。
- 标签分类显示出相当的总体性能,若包含题目描述则有改进;网页语言表现较差。
- 代码编译对 Go、PHP、Python、Ruby 和 C# 表现强劲,但对 Java、Kotlin 和 Rust 接近随机。
- 程序合成在某些语言上达到更高的 pass@k,但在 Rust 和其他资源较少的语言上落后;APR 在某些语言上显示相对更强的性能。
- 代码翻译表明 Kotlin 和 Go 对多数目标语言翻译效果良好,而 C++ 和 Python 是强势目标;跨语言翻译绩效因语言对而显著不同。
- Code-Code 与 NL-Code 检索,使用 StarEncoder 显示出取决于语言资源的结果,整体 NL-Code 表现更好;更大语料和语言资源不平衡影响 Code-Code 检索。
- 使用较小模型(Starcoderbase-3B、CodeLlama 变体)的实验显示数据有效性:较小的微调模型可以从 xCodeEval 数据中获益,而大型指令型模型在多种情形下仍优于较小的同行。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。