[论文解读] YaRN: Efficient Context Window Extension of Large Language Models
YaRN 引入一个针对性的 RoPE 插值方法,结合推理时的注意力温度缩放,以在最少微调和数据量下高效扩展 RoPE 基的 LLM 上下文窗口,实现最先进的扩展。它使 LLaMA-2 模型的上下文容量达到最多 128k,并在长序列上展示出强的迁移与性能。
Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize past the sequence length they were trained on. We present YaRN (Yet another RoPE extensioN method), a compute-efficient method to extend the context window of such models, requiring 10x less tokens and 2.5x less training steps than previous methods. Using YaRN, we show that LLaMA models can effectively utilize and extrapolate to context lengths much longer than their original pre-training would allow, while also surpassing previous the state-of-the-art at context window extension. In addition, we demonstrate that YaRN exhibits the capability to extrapolate beyond the limited context of a fine-tuning dataset. Code is available at https://github.com/jquesnelle/yarn
研究动机与目标
- Motivate and enable extending the context window of RoPE-based transformer models beyond pretraining limits.
- Propose YaRN, a targeted RoPE interpolation method with attention temperature scaling to preserve high-frequency information and local distances.
- Demonstrate compute-efficient fine-tuning (around 0.1% of data) and effective zero-shot/inference-time extrapolation.
- Evaluate YaRN on LLaMA/Llama 2 families for long-sequence perplexity, passkey retrieval, and standard benchmarks to show robustness and transferability.
提出的方法
- Formulate YaRN as a combination of NTK-by-parts interpolation (targeted interpolation across RoPE frequencies) and an attention temperature scaling (logits temperature t) implemented as a length-scaling trick.
- Define g(m) and h(θ_d) to interpolate RoPE dimensions selectively based on wavelength λ_d and context length L, using a ramp function γ to decide interpolation vs. no interpolation.
- Use NTK-by-parts with parameters α, β to categorize RoPE dimensions by r(d)=L/λ_d and apply linear interpolation with s when appropriate, while leaving high-frequency dimensions unaltered.
- In inference, apply Dynamic Scaling by updating the scale s per forward pass to gracefully extend beyond pretraining limits (Dynamic NTK).
- Train with a small fine-tuning dataset (PG19, 64k tokens per extension step) using low steps (400 steps for s=16, 200 steps for s=32) and standard optimization (AdamW, LR=2e-5).
- Provide a reproducible setup with code and evaluation tooling to reproduce Table 2, Figure 1, and Tables 1–5.]
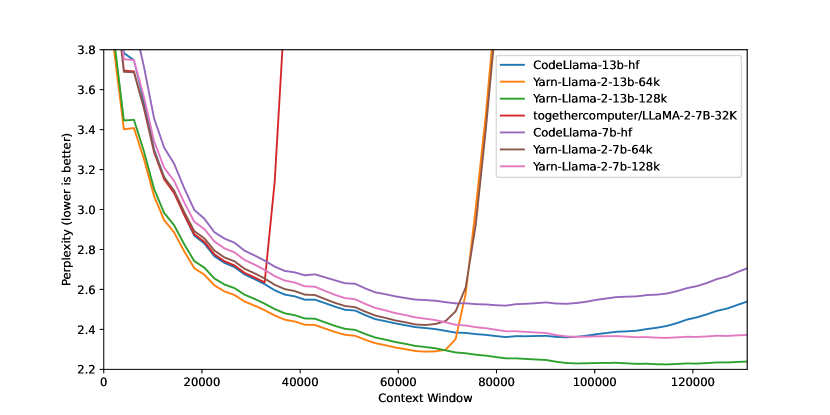
实验结果
研究问题
- RQ1Can RoPE-based LLMs generalize to context lengths significantly longer than their pretraining window using a compute-efficient interpolation method?
- RQ2How does a targeted interpolation (NTK-by-parts) combined with inference-time scaling (YaRN) perform compared to PI and NTK-aware approaches on long-context tasks?
- RQ3What are the transfer and extrapolation capabilities of YaRN across different model scales (7B, 13B) and after fine-tuning with limited data?
- RQ4Does YaRN preserve performance on standard benchmarks while extending context windows to very long lengths?
- RQ5Is there a practical, zero-shot/inference-time method to further extend context without retraining when using Dynamic Scaling?
主要发现
- YaRN achieves state-of-the-art context window extension with about 0.1% of pretraining data and 400 training steps for s=16 and 200 steps for s=32.
- YaRN enables LLaMA/Llama 2 models to extrapolate to 128k context with continued perplexity improvement at 128k for s=32.
- Compared to PI and NTK-aware baselines, YaRN shows superior long-context perplexity and passkey retrieval performance, with minimal degradation on standard benchmarks.
- Dynamic NTK (Dynamic Scaling) allows extending context without fine-tuning, and YaRN with NTK-by-parts and temperature scaling maintains performance across a wide range of context lengths.
- YaRN demonstrates strong transfer learning, enabling higher-scale context extension (s from 16 to 32) with transfer learning from the s=16 model without re-learning interpolated embeddings.
- On Open LLM benchmarks, YaRN models show negligible performance degradation relative to Llama 2 baselines, with average small drops between s=16 and s=32.

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。