[论文解读] Yi: Open Foundation Models by 01.AI
Yi 将6B和34B语言模型扩展为对话、长上下文(200K)、深度扩展以及视觉-语言变体,强调数据质量和可扩展基础设施,以在更低成本下达到GPT-3.5水平的性能。
We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
研究动机与目标
- 展示在大规模、经过仔细筛选的双语 English/Chinese 语料库上训练出的高性能6B和34B语言模型。
- 展示对对话、长上下文(200K)、深度扩展以及视觉-语言变体的扩展。
- 研究数据质量、预处理和对齐策略,提升基准测试表现及人类偏好。
- 提供可扩展的基础设施与优化技术,支持预训练、微调和高效推理/部署。
提出的方法
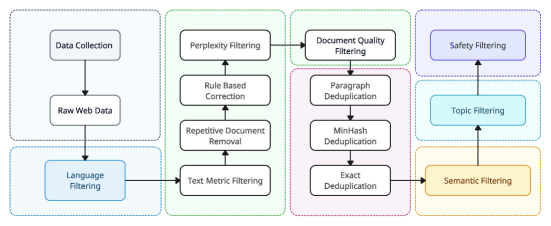
- 在 3.1T 双语 English/Chinese 代币上对 6B 和 34B 解码器‑仅 Transformer 进行预训练,采用级联去重和质量过滤。
- 结合 Grouped-Query Attention (GQA)、SwiGLU 激活,以及基于 Rotary/RoPE 的位置嵌入,并采用 RoPE ABF 来扩展长上下文。
- 使用 ChatML 格式提示,结合一个小型高质量指令数据集(<10K),进行微调,并进行分层数据混合网格搜索。
- 通过长序列预训练将上下文长度扩展至 200K,使用视觉编码器实现视语言对齐,并通过持续预训练实现深度扩展。
- 构建跨云调度、弹性训练和高效推理的全栈基础设施,使用 4 位/8 位量化、动态批处理和 PagedAttention。
实验结果
研究问题
- RQ1在大量数据清洗的前提下,规模在 6B/34B 的小到中等规模模型是否能在标准基准测试上达到 GPT-3.5 级别的性能?
- RQ2将上下文长度提高到 200K 并增加视语言对齐是否显著提升检索和多模态能力?
- RQ3通过持续预训练实现深度扩展对模型性能有何影响?
- RQ4数据质量与有针对性的微调如何影响人类偏好和跨任务的自动评估?
- RQ5哪些基础设施和优化技术能够实现大规模语言模型的成本高效预训练、微调与部署?
主要发现
| 模型 | 大小 | MMLU | BBH | C-Eval | CMMLU | 高考 | CR | RC | 代码 | 数学 |
|---|---|---|---|---|---|---|---|---|---|---|
| Yi | 6B | 63.2 | 42.8 | 72.0 | 75.5 | 72.2 | 72.2 | 68.7 | 21.1 | 18.6 |
| Yi | 34B | 76.3 | 54.3 | 81.4 | 83.7 | 82.8 | 80.7 | 76.5 | 32.1 | 40.8 |
- Yi-34B 在许多基准上达到与 GPT-3.5 相当的性能,并在评估中提供强烈的人类偏好信号。
- Yi-34B 实现了 200K 的上下文长度,经过长上下文训练和量化后几乎不损失性能。
- 4 位量化配合 8 位 KV 缓存,在 MMLU/CMMLU 等基准上可获得显著的内存节省,且精度损失微小。
- 上下文学习实验表明在更大规模上出现新能力,Yi-34B 在多参数推理任务上表现出色。
- 视觉-语言扩展将视觉表示对齐到语言语义空间,启用多模态能力。
- Yi-34B-Chat 在自动评估和人工评估上均显示强劲结果,特别是在与数学相关和类似代码的任务相较于较小基线时。
![Figure 2: Yi’s pre-training data mixture. Overall our data consist of 3.1T high-quality tokens in Both English and Chinese, and come from various sources. Our major differences from existing known mixtures like LLaMA [ 76 ] and Falcon [ 56 ] are that we are bilingual, and of higher quality due to ou](https://ar5iv.labs.arxiv.org/html/2403.04652/assets/x2.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。