[论文解读] YOLOv10: Real-Time End-to-End Object Detection
YOLOv10 引入 NMS-free 训练,具备一致的双分配与 holistic efficiency-accuracy 设计,在各模型规模上实现端到端实时目标检测的最新水平。
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$ imes$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$ imes$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46\% less latency and 25\% fewer parameters for the same performance.
研究动机与目标
- 通过去除 NMS 后处理,推进 YOLO 的端到端实时目标检测边界。
- 开发用于 NMS-free 推理的一致双分配训练方案。
- 对 YOLO 组件进行整体的效率与准确性优化。
- 在 COCO 数据集上展示跨模型规模的最先进延迟-准确性权衡。
提出的方法
- 提出 Consistent Dual Assignments 以实现 NMS-free 训练,使用 dual label heads(one-to-many 用于丰富监督,one-to-one 用于推理)。
- 引入一个一致的匹配度量,将 one-to-one 与 one-to-many 分配联系起来,以实现监督的一致性。
- 实现以整体现实效性和准确性为驱动的模型设计,包括轻量级分类头、空间-通道解耦下采样,以及基于秩的模块设计。
- 探索以大核卷积和部分自注意力(PSA)模块提升在低成本下的性能的准确性驱动设计。
- 使用基于秩的分析在冗余处分配紧凑块(CIB),并按模型规模有选择地应用大核和 PSA。
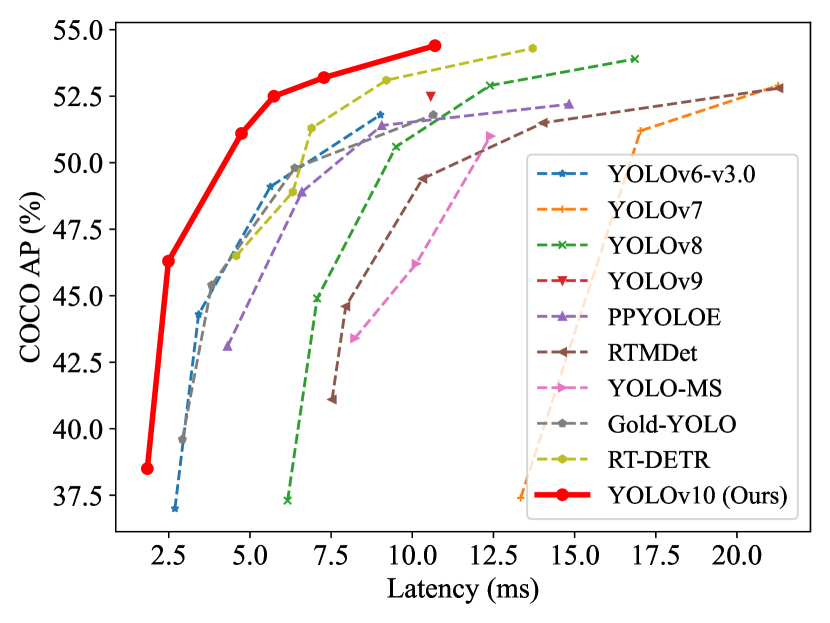
实验结果
研究问题
- RQ1端到端的 NMS-free YOLO 是否可以在 AP 上赶上或超过基于 NMS 的 YOLO,同时降低推理延迟?
- RQ2如何通过双标签分配和统一的匹配度量在不同头之间对齐监督以提高训练效率?
- RQ3哪些总体架构变化能够在不同模型规模上实现更好的效率-准确性权衡?
- RQ4在实时检测器中,大核卷积和 PSA 是否能在不产生过高成本的情况下带来收益?
- RQ5如何通过基于秩的块设计和解耦下采样在不影响性能的前提下降低冗余?
主要发现
- YOLOv10 在 COCO 数据集上实现了跨模型规模的最先进延迟-准确性权衡。
- YOLOv10-S 相较于 RT-DETR-R18 在 AP 相似的情况下更快 1.8 倍,同时参数和 FLOPs 少 2.8 倍。
- YOLOv10-B 相较于 YOLOv9-C,在相同性能下延迟降低 46%且参数减少 25%。
- YOLOv10-L 与 YOLOv10-X 在 AP 提升 0.3–1.0 的同时,参数显著减少(0.5–2.3 倍)。
- YOLOv10-N/S 在轻量模型中的 Latency 和 AP 超越 YOLOv6-3.0-N/S 与 RT-DETR 基线;端到端延迟相比某些基线降低约 70%。
![Figure 2: (a) Consistent dual assignments for NMS-free training. (b) Frequency of one-to-one assignments in Top-1/5/10 of one-to-many results for YOLOv8-S which employs $\alpha_{o2m}$ =0.5 and $\beta_{o2m}$ =6 by default [ 20 ] . For consistency, $\alpha_{o2o}$ =0.5; $\beta_{o2o}$ =6. For inconsiste](https://ar5iv.labs.arxiv.org/html/2405.14458/assets/x3.png)
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。