QUICK REVIEW
[论文解读] ZeroShotDataAug: Generating and Augmenting Training Data with ChatGPT
Solomon Ubani, Suleyman Olcay Polat|arXiv (Cornell University)|Apr 27, 2023
Topic Modeling被引用 19
一句话总结
本论文表明,ChatGPT 的零-shot 提示可以生成有效的合成训练数据,在 SST-2、SNIPS、TREC 上优于多种传统扩增方法,并与少样本 ChatGPT 相比。
ABSTRACT
In this paper, we investigate the use of data obtained from prompting a large generative language model, ChatGPT, to generate synthetic training data with the aim of augmenting data in low resource scenarios. We show that with appropriate task-specific ChatGPT prompts, we outperform the most popular existing approaches for such data augmentation. Furthermore, we investigate methodologies for evaluating the similarity of the augmented data generated from ChatGPT with the aim of validating and assessing the quality of the data generated.
研究动机与目标
- 通过向大语言模型(ChatGPT)发出提示,激发对低资源 NLP 任务的数据增强。
- 在多个数据集上,将零-shot 的 ChatGPT 数据增强与已建立的基线进行对比评估。
- 提出并评估衡量 ChatGPT 生成数据与原始数据相似性的方法,以验证质量。
- 量化增强规模如何影响性能,并在没有训练数据的情况下探索数据充足性。
提出的方法
- 将零-shot ChatGPT 增强与 EDA、Back-Translation 以及基于 transformer 的增强基线进行比较。
- 在低资源设置下使用三个数据集(SST-2、SNIPS、TREC)(每类 10 个样本)。
- 通过面向任务的零-shot 提示为 ChatGPT 生成合成数据,并在 15 次运行中进行评估。
- 使用增广数据对 BERT-base-uncased 进行微调,并报告准确率及标准差。
- 使用 Sentence Embedding (MiniLM)、TF-IDF 和 Word Overlap 指标评估数据污染和相似性。
- 尝试不同的增广样本数量,以研究性能趋势。
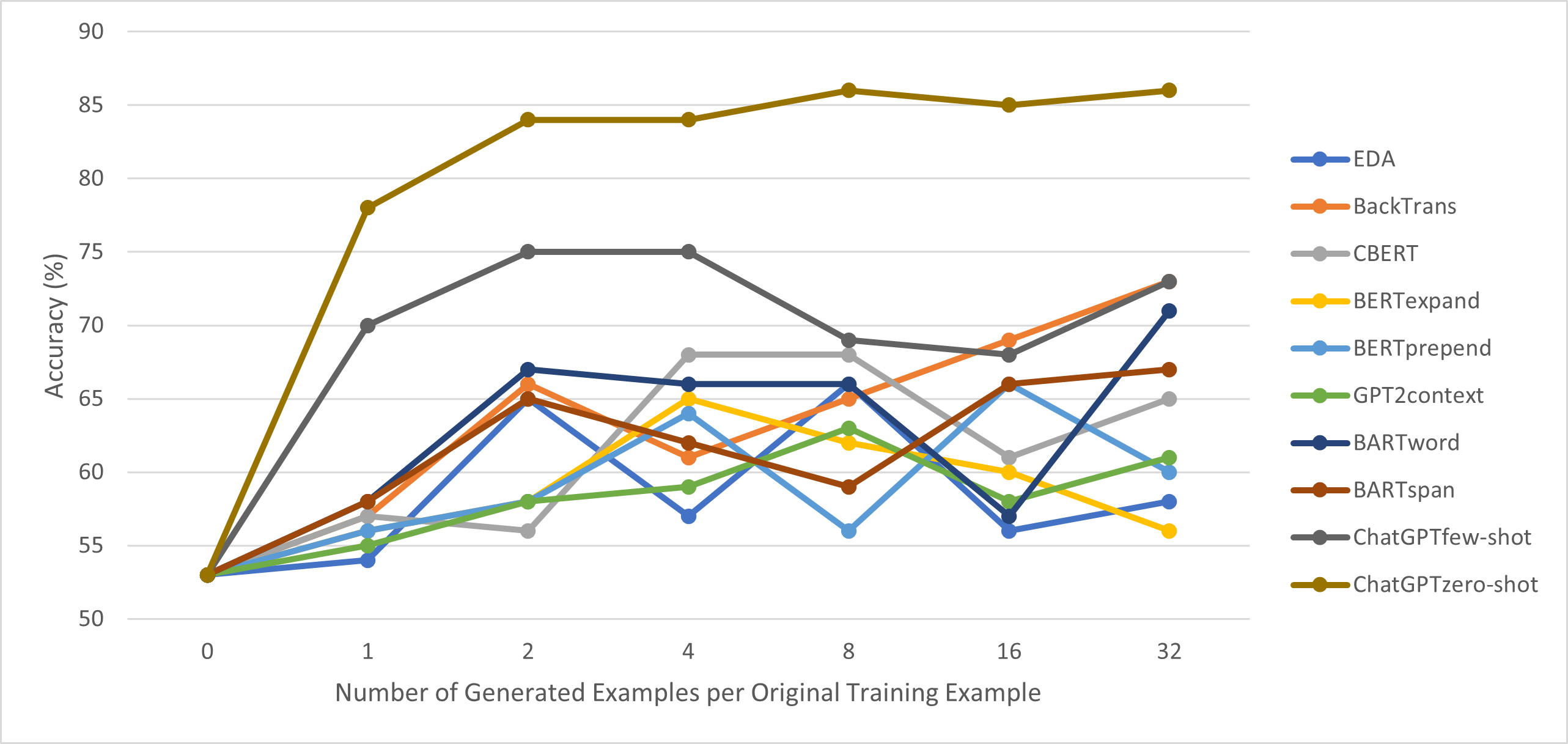
实验结果
研究问题
- RQ1与传统方法相比,零-shot ChatGPT 提示在文本分类任务上的数据增强有多有效?
- RQ2在低资源设置中,ChatGPT 生成数据的数量对模型性能有何影响?
- RQ3我们能否可靠地评估 ChatGPT 生成数据与真实数据之间的相似性,以排除记忆化或污染?
- RQ4即使没有任何原始训练数据,零-shot ChatGPT 增强是否也能优于其他方法?
主要发现
| 模型 | SST-2 | SNIPS | TREC |
|---|---|---|---|
| 无增广 | 52.9 (5.0) | 79.4 (3.2) | 48.6 (11.5) |
| EDA | 53.8 (4.4) | 85.8 (3.0) | 52.6 (10.5) |
| BackTrans. | 57.5 (5.6) | 86.5 (2.4) | 66.2 (8.5) |
| CBERT | 57.4 (6.7) | 85.8 (3.5) | 64.3 (10.9) |
| BERTexpand | 56.3 (6.5) | 86.1 (2.7) | 65.3 (6.1) |
| BERTprepend | 56.1 (6.3) | 86.8 (1.6) | 64.7 (9.6) |
| GPT2context | 55.4 (6.7) | 86.6 (2.7) | 54.3 (10.1) |
| BARTword | 58.0 (6.8) | 86.8 (2.6) | 63.7 (9.8) |
| BARTspan | 57.7 (7.1) | 87.2 (1.4) | 67.3 (6.1) |
| ChatGPTfew-shot | 69.6 (5.8) | 91.3 (1.4) | 66.7 (8.0) |
| ChatGPTzero-shot | 78.1 (5.1) | 91.2 (1.3) | 75.3 (4.0) |
- 零-shot ChatGPT 增强在 SST-2 上达到 78.1%、SNIPS 91.2%、TREC 75.3% 的准确率,除 SNIPS 上的少样本 ChatGPT 外,超越所有基线。
- 在 SST-2 和 TREC 上,零-shot ChatGPT 分别比最佳的非 ChatGPT 增强高出 20% 和 8%,在 SNIPS 上高出 4%。
- 随着每个原始样本的 ChatGPT 生成增广样本数量增加(K 在 {1,2,4,8,16,32}),性能提升仍然存在。
- 即使没有原始训练数据,ChatGPT 零-shot 增强的平均准确率为 0.80 (SST-2),0.78 (SNIPS),0.62 (TREC),在 SST-2 上与现有方法相比具有竞争力或更好,在 TREC 上接近最佳。
- 相似性分析(Cosine Sentence Embedding、Cosine TF-IDF、Word Overlap)显示几乎没有证据表明来自 ChatGPT 生成的数据存在记忆化或污染。
- 数据相似性结果表明,ChatGPT 生成的数据平均上比测试数据更接近训练数据,提示是泛化而非记忆。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。