[论文解读] REFINER: Reasoning Feedback on Intermediate Representations
REFINER 训练一个生成器产生中间推理步骤,一个批判者提供细粒度反馈,从而提升多种推理任务中的推理能力,包括数学文字题、合成自然语言推理以及道德故事生成。
Language models (LMs) have recently shown remarkable performance on reasoning tasks by explicitly generating intermediate inferences, e.g., chain-of-thought prompting. However, these intermediate inference steps may be inappropriate deductions from the initial context and lead to incorrect final predictions. Here we introduce REFINER, a framework for finetuning LMs to explicitly generate intermediate reasoning steps while interacting with a critic model that provides automated feedback on the reasoning. Specifically, the critic provides structured feedback that the reasoning LM uses to iteratively improve its intermediate arguments. Empirical evaluations of REFINER on three diverse reasoning tasks show significant improvements over baseline LMs of comparable scale. Furthermore, when using GPT-3.5 or ChatGPT as the reasoner, the trained critic significantly improves reasoning without finetuning the reasoner. Finally, our critic model is trained without expensive human-in-the-loop data but can be substituted with humans at inference time.
研究动机与目标
- 在语言模型中激发并实现对中间推理步骤的显式生成,同时降低错误推理的发生。
- 提出一个由生成器与批判者组成的交互循环,向中间表示提供细粒度反馈。
- 证明结构化反馈在多任务和不同模型规模上均能提升推理能力。
- 证明经过培训的批判者即使对外部大语言模型如 GPT-3.5 和 ChatGPT 也能提升推理能力。
- 提供对反馈、批判者质量和推理时使用等因素的消融研究与分析。
提出的方法
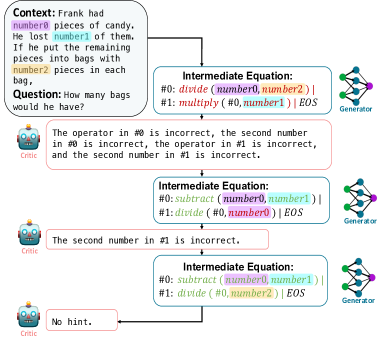
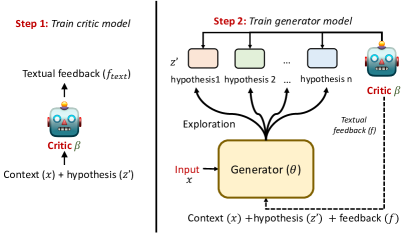
- 带有一个生成器和一个批判者的两模型 REFINER 框架。
- 批判者在自动构建的、描述推理错误的细粒度反馈数据上进行训练。
- 生成器经过微调以生成中间表示,并通过批判者反馈进行优化。
- 反馈是基于错误类型模板生成的半结构化文本,转化为自然语言供生成器使用。
- 训练过程通过核心采样进行探索,以让生成器接触多样化的反馈。
- 推理时使用经过训练的批判者来引导或纠正生成器的中间步骤。
实验结果
研究问题
- RQ1细粒度、结构化的中间推理步骤反馈是否能超越标量 rewards 改善最终任务性能?
- RQ2是否任务专家型的批判者能在多种推理任务中改善中间表示和最终答案?
- RQ3是否可在不微调外部 LLM(如 GPT-3.5、ChatGPT)的情况下,通过训练好的批判者提升其性能?
- RQ4REFINER 相对于自我 refinement 或自我一致性等其他 refinement 方法在各任务中的表现如何?
- RQ5REFINER 的增益对不完美(有噪声)批判者以及推理时使用的鲁棒性有多强?
主要发现
| 模型 | IR (z) | 答案 (y) |
|---|---|---|
| UQA-base | 34.1 | – |
| UQA-base + PPO | 31.5 | – |
| REFINER base | 47.2 | – |
| UQA-large | 46.7 | – |
| UQA-large + PPO | 48.2 | – |
| REFINER large | 53.8 | – |
| GPT-3.5 + CoT | 64.1 | 67.1 |
| GPT-3.5 + CoT + REFINER critic | 67.3 | 70.6 |
- REFINER 在数学文字题、合成自然语言推理和道德故事生成等任务上相较同等规模的基线具有显著提升。
- 在 MWP 上,IR (z) 由 34.1 提升到 REFINER base 的 47.2,再到 REFINER large 的 53.8;GPT-3.5 + CoT + REFINER critic 达到 67.3 IR 和 70.6 的最终准确率。
- 在 sNLR 上,REFINER 将 IR 提升至 53.8(基线 46.7),最终答案准确率也提升至 53.8?(表格显示 IR=53.8,Con=?),且在 large 情况下获得如 +2.9 EM 相对于 UQA-base 和 +6.8 EM 相对于 GPT-3.5 的增益。
- 在 MS 上,REFINER 将道德规范与行动相关性相较 UQA-large 基线提升约 20 点,Krippendorff 的 α 显示更高的一致性。
- 经训练的批判者单独使用即可显著提升 GPT-3.5 的少样本推理(如 MWP 和 sNLR 的增益分别为 +3.5、+6.8)。
- REFINER 的表现优于自我精炼方法,且与结合(如 Self-Consistency、ReACT)的 CoT 基方法共同使用时也能提升。
- 消融研究表明推理时批判者反馈的关键作用以及探索阶段的重要性;即使批判者不完美也能带来好处,而极度嘈杂的批判者可能会损害性能。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。