[论文解读] Can Generalist Foundation Models Outcompete Special-Purpose Tuning? Case Study in Medicine
本文表明提示工程(Medprompt)能够解锁GPT-4在医疗领域的专业能力,在九项医学基准测试中超越像Med-PaLM 2这样的现有专家模型,且调用模型次数更少。
Generalist foundation models such as GPT-4 have displayed surprising capabilities in a wide variety of domains and tasks. Yet, there is a prevalent assumption that they cannot match specialist capabilities of fine-tuned models. For example, most explorations to date on medical competency benchmarks have leveraged domain-specific training, as exemplified by efforts on BioGPT and Med-PaLM. We build on a prior study of GPT-4's capabilities on medical challenge benchmarks in the absence of special training. Rather than using simple prompting to highlight the model's out-of-the-box capabilities, we perform a systematic exploration of prompt engineering. We find that prompting innovation can unlock deeper specialist capabilities and show that GPT-4 easily tops prior leading results for medical benchmarks. The prompting methods we explore are general purpose, and make no specific use of domain expertise, removing the need for expert-curated content. Our experimental design carefully controls for overfitting during the prompt engineering process. We introduce Medprompt, based on a composition of several prompting strategies. With Medprompt, GPT-4 achieves state-of-the-art results on all nine of the benchmark datasets in the MultiMedQA suite. The method outperforms leading specialist models such as Med-PaLM 2 by a significant margin with an order of magnitude fewer calls to the model. Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset over the best methods to date achieved with specialist models and surpasses a score of 90% for the first time. Beyond medical problems, we show the power of Medprompt to generalize to other domains and provide evidence for the broad applicability of the approach via studies of the strategy on exams in electrical engineering, machine learning, philosophy, accounting, law, nursing, and clinical psychology.
研究动机与目标
- 证明通用基础模型在医学领域无需广泛微调即可达到或超过专业模型的性能。
- 系统性地探索提示工程技术以解锁领域特定能力。
- 开发并评估一个成本效益高、具有广泛适用性的通用提示框架(Medprompt)。
提出的方法
- 在嵌入空间中使用k-NN进行动态少样本示例选择,以挑选相关的训练样本。
- 由GPT-4自动生成的思维链提示,并附带一个验证步骤。
- 选项洗牌集成以降低选项位置偏差并提高鲁棒性。
- 将上述方法整合到一个包含预处理和推理阶段的两阶段Medprompt工作流中。
- 采用稳健的评估设计,使用盲态保留数据集以避免对提示的过拟合。
- 消融研究以量化各个Medprompt组件的贡献。
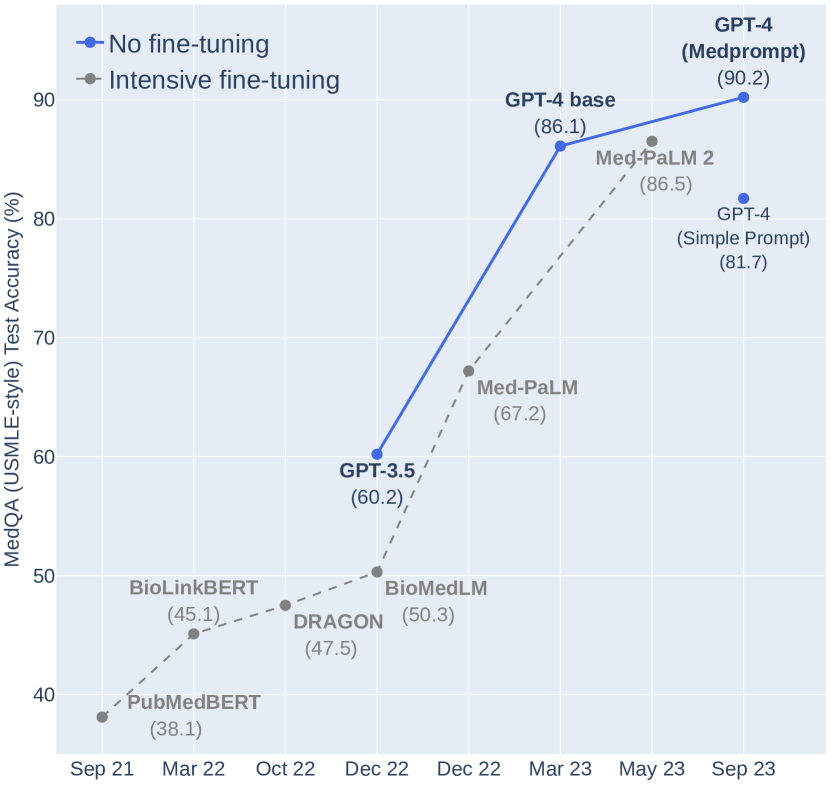
实验结果
研究问题
- RQ1通用基础模型是否能够在医学挑战基准上达到或超过最先进水平,而无需领域特定微调?
- RQ2哪些提示组件对医学问答任务的性能提升贡献最大?
- RQ3Medprompt对非医疗领域和能力考试的泛化能力如何?
- RQ4在评估保留数据时,提示设计对过拟合与泛化有何影响?
主要发现
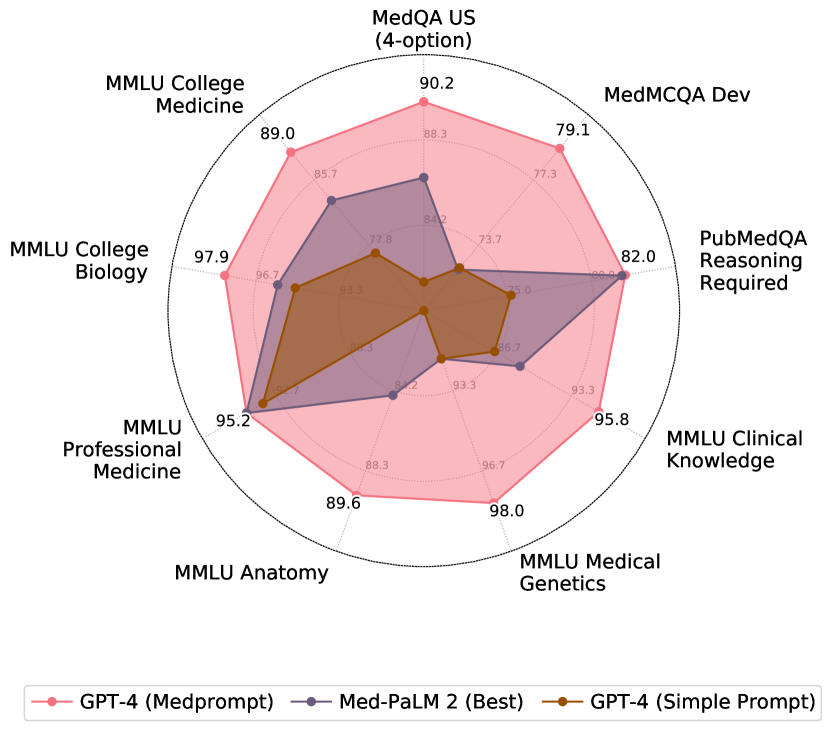
- 结合Medprompt的GPT-4在九个MultiMedQA数据集上超过所有基线,包括MedQA、MedMCQA、PubMedQA和MMLU医学子集。
- 在MedQA(USMLE风格)上,在特定设置下,Medprompt达到90.6%的准确率,相较于以往最佳专家方法错误率降低了27%。
- 自生成的思维链提示在Medprompt组件中贡献最大,其次是少样本示例和选项洗牌集成。
- Medprompt对医学以外的领域能力考试显示出强泛化能力,在跨领域的基线零样本基础上平均提升约7.3个百分点。
- 盲评保留集测试显示性能与盲评测试相当或更高,表明对基准提示的过拟合风险较低。
- 消融分析表明若增加更多示例和集成步骤,可能带来进一步提升,但计算成本更高。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。