[论文解读] Retrieving Evidence from EHRs with LLMs: Possibilities and Challenges
本论文在零-shot设定中研究使用 Flan-T5 XXL 检索并总结与放射学相关诊断的非结构化 EHR 证据,结果表明与标准信息检索基线相比,LLM 输出更受偏好,但易产生幻觉;置信度信号可能有助于识别并缓解幻觉。
Unstructured data in Electronic Health Records (EHRs) often contains critical information-complementary to imaging-that could inform radiologists' diagnoses. But the large volume of notes often associated with patients together with time constraints renders manually identifying relevant evidence practically infeasible. In this work we propose and evaluate a zero-shot strategy for using LLMs as a mechanism to efficiently retrieve and summarize unstructured evidence in patient EHR relevant to a given query. Our method entails tasking an LLM to infer whether a patient has, or is at risk of, a particular condition on the basis of associated notes; if so, we ask the model to summarize the supporting evidence. Under expert evaluation, we find that this LLM-based approach provides outputs consistently preferred to a pre-LLM information retrieval baseline. Manual evaluation is expensive, so we also propose and validate a method using an LLM to evaluate (other) LLM outputs for this task, allowing us to scale up evaluation. Our findings indicate the promise of LLMs as interfaces to EHR, but also highlight the outstanding challenge posed by "hallucinations". In this setting, however, we show that model confidence in outputs strongly correlates with faithful summaries, offering a practical means to limit confabulations.
研究动机与目标
- 动机:使用大语言模型(LLMs)与非结构化 EHR 笔记对接,以帮助放射科医生进行诊断。
- 评估一种零-shot 提示策略,以判断患者是否患有某疾病或存在风险,并对支持证据进行摘要。
- 将基于 LLM 的检索与神经嵌入基线进行比较,并评估专家(放射科医生)对证据的有用性与可靠性判断。
- 描述 LLM 输出中的幻觉现象,并探索模型置信度信号作为潜在探测器。
- 讨论在安全部署面向 EHR 的 LLM 时的局限性和未来研究方向。
提出的方法
- 以 Flan-T5 XXL 作为基础 LLM,对临床笔记进行零-shot 推理,以诊断特定疾病。
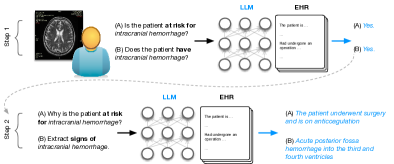
- 应用顺序提示策略:先判断是否存在风险或诊断,再在结果为阳性时提取支持证据。
- 与检索基线 CBERT(神经嵌入)进行比较,使用 GPT-3.5 生成风险因素短语,并使用 ClinicalBERT 进行句子嵌入。
- 由经验丰富的放射科医生对证据进行评估,将相关性和笔记中的存在作为基线,使用 0–3 的有用性量表。
- 通过 LM 似然性和自洽性提示分析模型置信度,以检测幻觉并与有用性相关。
实验结果
研究问题
- RQ1零-shot LLM 能否从非结构化 EHR 笔记中判断患者是否处于某诊断的风险或已患该病?
- RQ2与神经嵌入检索基线相比,LLM 生成证据的质量与可信度如何?
- RQ3LLM 幻觉证据的频率有多高,置信度信号是否能有效识别幻觉?
- RQ4放射科医生是否更偏好 abstractive 的 LLM 输出来呈现与总结证据,相较于 extractive 基线?
- RQ5该方法对查询术语变异和数据集来源的鲁棒性如何?
主要发现
- LLM 生成的证据在有用性和简洁性方面常被放射科医生偏好,优于 CBERT 基线。
- HALA:在评估样本中,约 9.4% 的 FLAN-T5 证据存在幻觉。
- 放射科医生判断 FLAN-T5 证据在 MIMIC 中有用/非常有用的比例为 41.5%,在 BWH 为 48.4%;相对的幻觉比例为 23.0%(MIMIC)和 18.5%(BWH)。
- 模型置信度分数(似然性与自洽性)在区分幻觉方面具有鲁棒性(AUC > 0.9),并与有用性相关。
- 从笔记识别未来诊断的召回率在一个子集研究中达到 0.7(140/200 正确)。
- 放射科医生报告称 abstractive 的 FLAN-T5 输出比 extractive 片段提供更精确、简洁的摘要。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。