[论文解读] FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search
FBNet 使用可微分神经网络架构搜索来设计硬件感知的卷积神经网络,优化目标设备,在低延迟和降低搜索成本的同时实现高准确率。FBNet-B 在 ImageNet 上达到 74.1% 的 top-1,FLOPs 295M,Samsung S8 上延迟 23.1 ms,与 prior NAS 方法相比显著降低的搜索成本。
Designing accurate and efficient ConvNets for mobile devices is challenging because the design space is combinatorially large. Due to this, previous neural architecture search (NAS) methods are computationally expensive. ConvNet architecture optimality depends on factors such as input resolution and target devices. However, existing approaches are too expensive for case-by-case redesigns. Also, previous work focuses primarily on reducing FLOPs, but FLOP count does not always reflect actual latency. To address these, we propose a differentiable neural architecture search (DNAS) framework that uses gradient-based methods to optimize ConvNet architectures, avoiding enumerating and training individual architectures separately as in previous methods. FBNets, a family of models discovered by DNAS surpass state-of-the-art models both designed manually and generated automatically. FBNet-B achieves 74.1% top-1 accuracy on ImageNet with 295M FLOPs and 23.1 ms latency on a Samsung S8 phone, 2.4x smaller and 1.5x faster than MobileNetV2-1.3 with similar accuracy. Despite higher accuracy and lower latency than MnasNet, we estimate FBNet-B's search cost is 420x smaller than MnasNet's, at only 216 GPU-hours. Searched for different resolutions and channel sizes, FBNets achieve 1.5% to 6.4% higher accuracy than MobileNetV2. The smallest FBNet achieves 50.2% accuracy and 2.9 ms latency (345 frames per second) on a Samsung S8. Over a Samsung-optimized FBNet, the iPhone-X-optimized model achieves a 1.4x speedup on an iPhone X.
研究动机与目标
- 解决移动设备 ConvNet 设计中准确率与真实硬件延迟之间的不匹配。
- Develop a differentiable NAS (DNAS) framework to efficiently search layer-wise architectures tailored to target hardware.
- Define a latency-aware loss and a differentiable latency estimator to guide architecture search.
- Demonstrate FBNet models that outperform manually designed and other automatically searched models on mobile benchmarks.
提出的方法
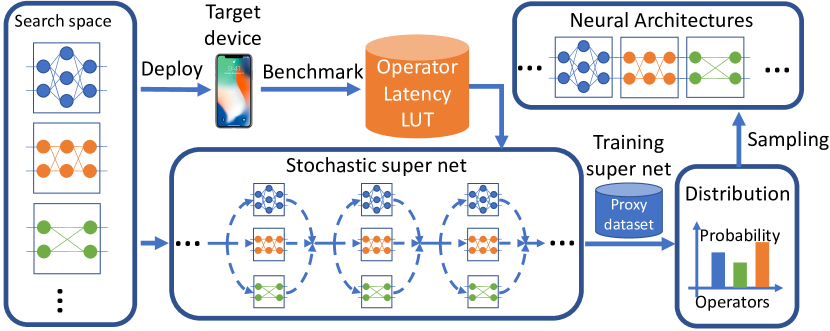
- Represent the search space as a layer-wise macro-architecture with 22 layers and 9 candidate blocks per layer.
- Use a stochastic super net where each layer samples a block with probability via Gumbel-Softmax to enable gradient-based optimization.
- Define a latency-aware loss as L(a,w)=CE(a,w) * alpha * log(LAT(a))^beta, where LAT(a) is estimated by a differentiable latency lookup table.
- Estimate LAT(a) as LAT(a)=sum_l LAT(b_l^(a)) to make latency differentiable w.r.t. architecture choices.
- Train weights w_a of all operators as in standard CNN training while updating architecture parameters theta to favor higher-accuracy, lower-latency blocks.
- Sample final architectures from the learned distribution P_theta and train them from scratch for evaluation.
实验结果
研究问题
- RQ1Can differentiable neural architecture search (DNAS) efficiently discover hardware-aware ConvNets tailored to target mobile devices?
- RQ2Does incorporating a latency-aware objective yield architectures with lower actual latency without sacrificing accuracy?
- RQ3How does layer-wise block flexibility (vs. cell-level reuse) impact accuracy and latency on real hardware?
- RQ4What are the attainable accuracy-latency trade-offs across different input resolutions and channel scaling?
- RQ5Do device-specific latency characteristics justify separate networks per target device?
主要发现
| 模型 | 搜索 | 空间 | 搜索成本(GPU 小时 / 相对) | 参数数量 | FLOPs | CPU 延迟 | 延迟 | Top-1 准确率 (%) |
|---|---|---|---|---|---|---|---|---|
| 1.0-MobileNetV2 | manual | - | - | 3.4M | 300M | 21.7 ms | - | 72.0 |
| 1.5-ShuffleNetV2 | manual | - | - | 3.5M | 299M | 22.0 ms | - | 72.6 |
| CondenseNet (G=C=8) | manual | - | - | 2.9M | 274M | 28.4 ms | - | 71.0 |
| MnasNet-65 | RL | stage-wise | 91K ∗ / 421x | 3.6M | 270M | - | - | 73.0 |
| DARTS | gradient | cell | 288 / 1.33x | 4.9M | 595M | - | - | 73.1 |
| FBNet-A (ours) | gradient | layer-wise | 216 / 1.0x | 4.3M | 249M | 19.8 ms | - | 73.0 |
| 1.3-MobileNetV2 | manual | - | - | 5.3M | 509M | 33.8 ms | - | 74.4 |
| CondenseNet (G=C=4) | manual | - | - | 4.8M | 529M | 28.7 ms | - | 73.8 |
| MnasNet-65 | RL | stage-wise | - | 4.2M | 317M | - | - | 74.0 |
| NASNet-A | RL | cell | - | 5.3M | 564M | - | - | 74.0 |
| PNASNet | SMBO | cell | - | 5.1M | 588M | - | - | 74.2 |
| FBNet-B (ours) | gradient | layer-wise | 216 / 1.0x | 4.5M | 295M | 23.1 ms | - | 74.1 |
| 1.4-MobileNetV2 | manual | - | - | 6.9M | 585M | 37.4 ms | - | 74.7 |
| 2.0-ShuffleNetV2 | manual | - | - | 7.4M | 591M | 33.3 ms | - | 74.9 |
| MnasNet-92 | RL | stage-wise | - | 4.4M | 388M | - | - | 74.8 |
| FBNet-C (ours) | gradient | layer-wise | 216 / 1.0x | 5.5M | 375M | 28.1 ms | - | 74.9 |
- FBNet 模型在与最先进高效网络相比时,仍能达到具有竞争力甚至更高的准确率,同时具有更低的延迟和 FLOPs。
- FBNet-B 在 Samsung S8 上达到 74.1% 的 top-1 准确率,FLOPs 为 295M,延迟 23.1 ms,优于 MobileNetV2-1.3,并在比 MnasNet 更低的搜索成本下接近其性能。
- DNAS 将搜索成本显著降低到约 216 GPU-hours,比 MnasNet 快约 421 倍,在所报告的比较中也比 NAS/PNAS/DARTS 快数量级。
- 将 DNAS 扩展到不同输入分辨率和通道尺度,在相似延迟下相比 MobileNetV2 基线获得 1.5% 到 6.4% 的绝对准确率提升。
- FBNet-small 变体在保持合理准确率的同时实现非常低的延迟(低至 2.9 ms),并且设备特定的优化(iPhone X 与 Samsung S8)显著提升设备端速度。
- FBNet-iPhoneX 与 FBNet-S8 显示架构选择会自适应设备特定的运行时,验证了为每个设备进行硬件感知设计的必要性。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。