[论文解读] Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models
本文通过应用一系列开放域、案例法问答任务分析大型语言模型中的法律幻觉,揭示高幻觉率以及在检测或纠正错误法律内容方面的局限性。
Do large language models (LLMs) know the law? These models are increasingly being used to augment legal practice, education, and research, yet their revolutionary potential is threatened by the presence of hallucinations -- textual output that is not consistent with legal facts. We present the first systematic evidence of these hallucinations, documenting LLMs' varying performance across jurisdictions, courts, time periods, and cases. Our work makes four key contributions. First, we develop a typology of legal hallucinations, providing a conceptual framework for future research in this area. Second, we find that legal hallucinations are alarmingly prevalent, occurring between 58% of the time with ChatGPT 4 and 88% with Llama 2, when these models are asked specific, verifiable questions about random federal court cases. Third, we illustrate that LLMs often fail to correct a user's incorrect legal assumptions in a contra-factual question setup. Fourth, we provide evidence that LLMs cannot always predict, or do not always know, when they are producing legal hallucinations. Taken together, our findings caution against the rapid and unsupervised integration of popular LLMs into legal tasks. Even experienced lawyers must remain wary of legal hallucinations, and the risks are highest for those who stand to benefit from LLMs the most -- pro se litigants or those without access to traditional legal resources.
研究动机与目标
- 构建一个法律幻觉的类型学框架,以为未来研究提供框架。
- 量化LLM对可验证法律问题的回答中事实性不准确性的发生率。
- 评估LLMs处理对照-事实前提的能力并评估它们对答案的自信度。
- 调查模型性能如何随案情年龄、知名度和法院等级而变化,以识别法律推理中的单一文化现象。
提出的方法
- 创建一个原始的14项法律研究任务,难度递增(存在、法院、引文、作者、处分、引述、权威、推翻年份、教义一致、事实背景、程序姿态、后续历史、核心法律问题、中心裁定)。
- 使用基于参考的查询,并结合Caselaw Access Project、Supreme Court Database等来源的真实元数据来计算人群幻觉率。
- 应用两种查询范式:基于参考的(真实答案)和无参考的(基于矛盾,GPT-4裁决)。
- 在四个任务类别(低、适中、高复杂度)下,对三种LLM(ChatGPT 3.5、PaLM 2、Llama 2)进行零-shot和少量-shot提示。
- 将幻觉率计算为参考型任务中输出错误占比与真实答案的比例,以及来自无参考的基于矛盾的任务的下界。
实验结果
研究问题
- RQ1当LLMs回答关于案件的可验证法律问题时,开放域幻觉的流行程度如何?
- RQ2幻觉率是否随任务复杂性、法院等级、管辖区、案件知名度和年份在不同LLM之间变化?
- RQ3LLMs是否易受 contra-factual bias 影响,并且它们是否能够可靠地评估自己对法律答案的确定性?
- RQ4更高温度、非贪婪的提示是否会产生更多的矛盾,指示非事实性输出?
主要发现
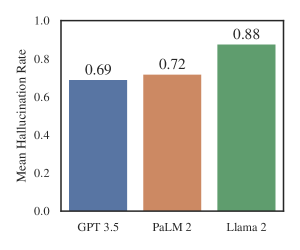
- 幻觉现象广泛,在可验证的联邦案件问题上,ChatGPT 3.5 的查询中发现为69%,Llama 2 为88%。
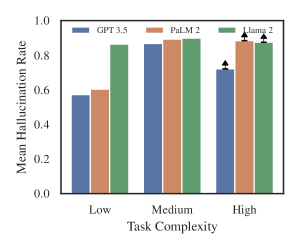
- 幻觉率随任务复杂性上升,在较新、较显著且更突出管辖区的情形下较低。
- LLMs 常对 contra-factual 问题给出错误答案,且在事后重新校准前难以可靠评估对答案的确定性。
- 参考无参考方法为幻觉率设定下界,高复杂度任务如核心法律问题和中心裁定显示出大量非事实性输出。
- 在更简单的任务和更高质量或更著名的案件中表现通常更好,揭示了LLMs中的法律单一文化效应。
- 总体而言,当前的LLMs 在关键法律任务上并不可靠,使用时应谨慎,尤其对像自诉诉讼人等脆弱用户。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。