[论文解读] Multi-Agent Reinforcement Learning: Methods, Applications, Visionary Prospects, and Challenges
本综述回顾多智能体强化学习方法、应用以及对可信多智能体强化学习的愿景,强调在人与机系统中安全性、鲁棒性、泛化、伦理约束和人机交互。
Multi-agent reinforcement learning (MARL) is a widely used Artificial Intelligence (AI) technique. However, current studies and applications need to address its scalability, non-stationarity, and trustworthiness. This paper aims to review methods and applications and point out research trends and visionary prospects for the next decade. First, this paper summarizes the basic methods and application scenarios of MARL. Second, this paper outlines the corresponding research methods and their limitations on safety, robustness, generalization, and ethical constraints that need to be addressed in the practical applications of MARL. In particular, we believe that trustworthy MARL will become a hot research topic in the next decade. In addition, we suggest that considering human interaction is essential for the practical application of MARL in various societies. Therefore, this paper also analyzes the challenges while MARL is applied to human-machine interaction.
研究动机与目标
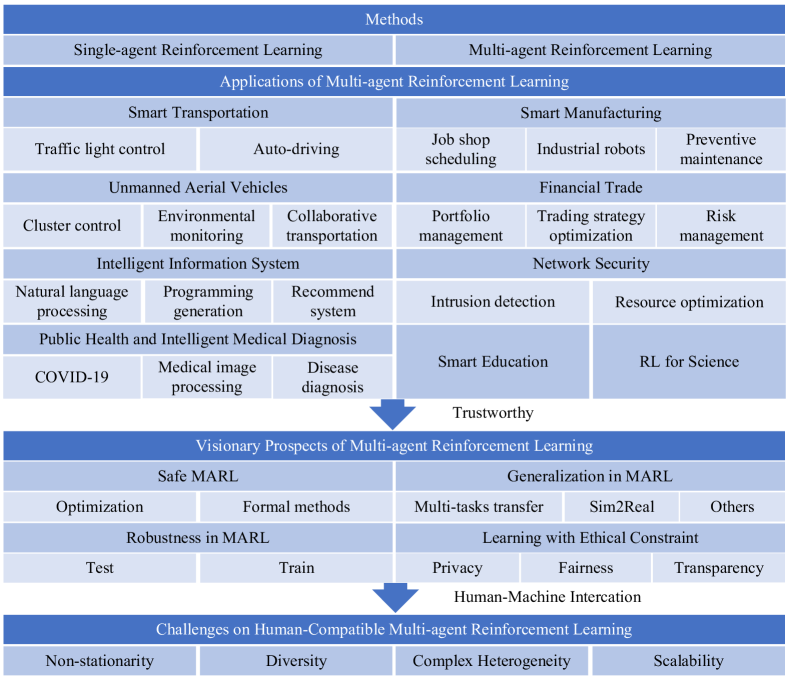
- 概述基本的 MARL 方法及典型应用场景。
- 概述实际 MARL 中的安全性、鲁棒性、泛化和伦理约束。
- 强调在人机系统的实际应用中, MARL 中人机交互的重要性。
- 讨论未来十年可信 MARL 的挑战与前景。
提出的方法
- 描述单智能体 RL 的基础与关键方程(马尔可夫决策过程 MDP、Q-learning、DQN、策略梯度、确定性策略梯度 DPG)。
- 通过随机博弈和联合 Q/V 函数介绍多智能体形式化。
- 讨论通过 CTDE 学习协作,包括 VDN、QMIX、QTRAN、QPLEX,以及基于注意力/均场方法。
- 讨论学习通信方法(强化型与可微分)及拓扑学习。
- 概述均场 MARL 及大规模智能体群体的可扩展性策略。
- 涉及人参与考虑以及四个信任相关维度(安全性、鲁棒性、泛化、伦理约束)。
实验结果
研究问题
- RQ1主要的 MARL 方法学分支及其训练范式是什么?
- RQ2MARL 已被应用于哪些领域,并采用了何种方法学选择?
- RQ3在 MARL 中,安全性、鲁棒性、泛化和伦理约束方面的关键局限性是什么?
- RQ4如何将人机系统中的人机互动集成到 MARL 中?
- RQ5未来十年定义可信 MARL 的挑战与远景前景是什么?
主要发现
- 集中训练、去中心化执行(CTDE)是协作型 MARL 的主导范式。
- 基于价值的方法(VDN、QMIX、QTRAN、QPLEX)和基于策略的方法(MADDPG及带注意力的变体)解决 MARL 中的信用分配和可扩展性问题。
- 学习通信(强化型与可微分)以及基于图的/拓扑感知方法在多智能体场景中提升协作。
- 均场 MARL 通过用平均效应或基于邻域的观测来近似交互,提供对大量智能体群体的可扩展性。
- 应用涵盖智能交通、无人机、智能信息系统、制造业和金融业,展示了 MARL 的多样性以及对人机互动考量的需求。

更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。