[论文解读] Simple random search provides a competitive approach to reinforcement learning
作者展示,在线性策略的参数空间中进行简单的增强随机搜索,可以达到或超过 MuJoCo 运动任务的最先进样本效率,并且在计算效率方面远优于进化策略。它们还强调在 RL 基准测试中种子和超参数的高方差。
A common belief in model-free reinforcement learning is that methods based on random search in the parameter space of policies exhibit significantly worse sample complexity than those that explore the space of actions. We dispel such beliefs by introducing a random search method for training static, linear policies for continuous control problems, matching state-of-the-art sample efficiency on the benchmark MuJoCo locomotion tasks. Our method also finds a nearly optimal controller for a challenging instance of the Linear Quadratic Regulator, a classical problem in control theory, when the dynamics are not known. Computationally, our random search algorithm is at least 15 times more efficient than the fastest competing model-free methods on these benchmarks. We take advantage of this computational efficiency to evaluate the performance of our method over hundreds of random seeds and many different hyperparameter configurations for each benchmark task. Our simulations highlight a high variability in performance in these benchmark tasks, suggesting that commonly used estimations of sample efficiency do not adequately evaluate the performance of RL algorithms.
研究动机与目标
- 揭示在参数空间的探索是否能像动作空间的探索一样有效,用于无模型的 RL。
- 开发一个最小、无导数的优化方法,用于训练线性策略,具有计算效率。
- 在标准 MuJoCo 运动基准和一个困难的 LQR 实例上评估 ARS,以评估不同种子下的性能与鲁棒性。
- 突出 RL 性能在不同种子和超参数上的变异性,以指导基准测试实践。
提出的方法
- 提出一个用于 RL 的无导数优化的基本随机搜索(BRS)基线。
- 在 BRS 的基础上增加以奖励标准差进行缩放、在线状态归一化,以及舍弃表现较差的方向(ARS)。
- 引入四种 ARS 变体:V1、V1-t、V2、V2-t,V2 包括状态白化,V1/V2-t 使用前方向选择。
- 使用带有共享噪声表和独立 rollout 的并行实现,以估计沿随机方向的梯度。
- 为 RL 形式化一个 oracle 模型,以将样本复杂性视为对环境的 rollouts(查询)的数量。
- 在 MuJoCo 任务上将 ARS 与 NG、TRPO、ES、PPO、A2C、CEM 和 SAC 进行比较,并分析样本效率与墙钟时间。
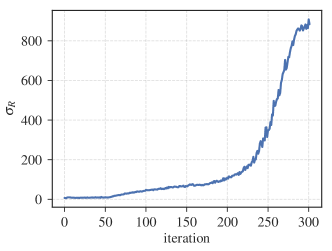
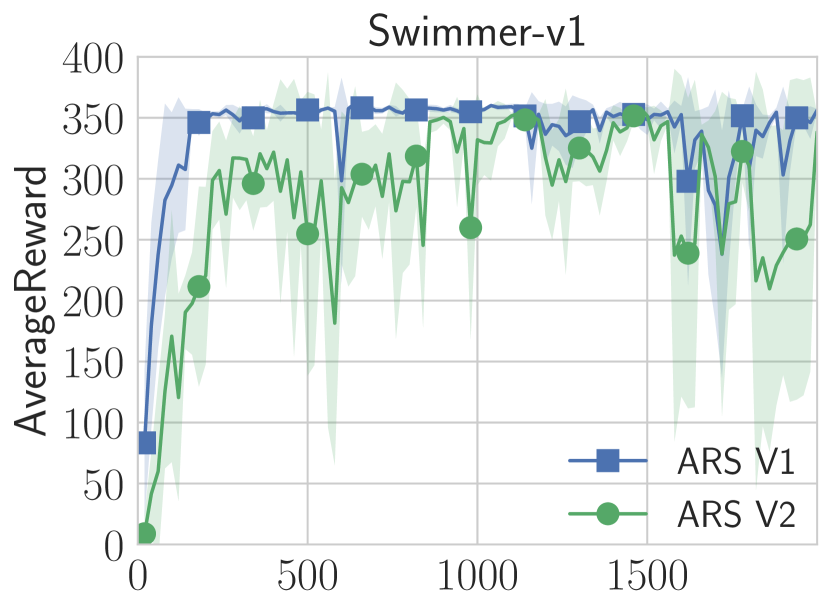
实验结果
研究问题
- RQ1在策略参数空间中进行一个简单的随机搜索,是否能在连续控制任务上实现具有竞争力的样本效率?
- RQ2诸如奖励缩放、状态归一化以及前方向选择等增广是否能提升 ARS 的性能?
- RQ3在 MuJoCo 基准测试中,ARS 在样本效率和计算成本方面与主流 RL 方法相比如何?
- RQ4评估种子可变性和超参数敏感性对 RL 基准测试实践的影响?
- RQ5由 ARS 训练的线性策略在具有挑战性的控制任务和未知动力学问题(如困难的 LQR 实例)上是否表现良好?
主要发现
| 任务 | 阈值 | ARS V1 | ARS V1-t | ARS V2 | ARS V2-t | NG-lin | NG-rbf | TRPO-nn |
|---|---|---|---|---|---|---|---|---|
| Swimmer-v1 | 325 | 100 | 100 | 427 | 427 | 1450 | 1550 | N/A |
| Hopper-v1 | 3120 | 89493 | 51840 | 3013 | 1973 | 13920 | 8640 | 10000 |
| HalfCheetah-v1 | 3430 | 10240 | 8106 | 2720 | 1707 | 11250 | 6000 | 4250 |
| Walker2d-v1 | 4390 | 392000 | 166133 | 89600 | 24000 | 36840 | 25680 | 14250 |
| Ant-v1 | 3580 | 101066 | 58133 | 60533 | 20800 | 39240 | 30000 | 73500 |
| Humanoid-v1 | 6000 | N/A | N/A | 142600 | 142600 | ≈130000 | ≈130000 | UNK |
- ARS 在 MuJoCo 运动任务的线性策略(无神经网络)上达到或超过最先进的样本效率。
- 在 Humanoid-v1 上达到类似性能阈值时,ARS 的计算效率至少比 ES 高出 15 倍。
- ARS 在种子和超参数方面表现出高方差,强调需要进行大量试验的广泛基准测试。
- ARS V2(带状态归一化/白化)解决了 Humanoid-v1,并相对于 V1 在大多数 MuJoCo 任务上提升了性能。
- ARS 可以将未知动力学的 LQR 问题的一个困难实例解决到几乎最优的性能。
- 与大量基线相比,ARS 在 1e6 时间步后通常实现有利的样本效率和具竞争力的最大回报。
更好的研究,从现在开始
从论文设计到论文写作,大幅缩短您的研究时间。
无需绑定信用卡
本解读由 AI 生成,并经人工编辑审核。