[논문 리뷰] A Comprehensive Survey on Data Augmentation
이 논문은 다섯 가지 데이터 모달리티(image, text, graph, tabular, time-series)에 걸친 데이터 증강 및 설문 기법을 모달리티에 독립적이고 데이터 중심적으로 분류하는 TAXONOMY를 제안합니다.
Data augmentation is a series of techniques that generate high-quality artificial data by manipulating existing data samples. By leveraging data augmentation techniques, AI models can achieve significantly improved applicability in tasks involving scarce or imbalanced datasets, thereby substantially enhancing AI models' generalization capabilities. Existing literature surveys only focus on a certain type of specific modality data and categorize these methods from modality-specific and operation-centric perspectives, which lacks a consistent summary of data augmentation methods across multiple modalities and limits the comprehension of how existing data samples serve the data augmentation process. To bridge this gap, this survey proposes a more enlightening taxonomy that encompasses data augmentation techniques for different common data modalities by investigating how to take advantage of the intrinsic relationship between and within instances. Additionally, it categorizes data augmentation methods across five data modalities through a unified inductive approach.
연구 동기 및 목표
- 데이터가 희소하거나 불균형한 데이터셋을 다루고 일반화를 개선하기 위한 데이터 증강의 필요성에 대한 동기 부여.
- 데이터 증강에 대한 모달리티 독립적, 데이터 중심의 TAXONOMY를 제안.
- 다섯 가지 데이터 모달리티를 통합 유도적 접근으로 분류하며 증강 기법을 범주화.
- 각 모달리티에서 정보를 활용하여 증강에 활용될 수 있는 방법 분석.
- 데이터 증강 방법의 최신 정합성 및 이론적 근거에 대한 종합적 정리.
제안 방법
- 데이터 증강을 라벨이 있는 데이터셋을 증강된 데이터셋으로 변환하는 함수 f_theta로 정식화.
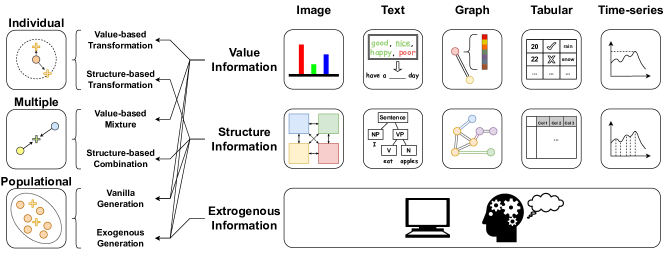
- 정보 원천에 따른 2단계 TAXONOMY 도입: Individual, Multiple, 및 Populational Augmentation.
- 또한 (i) 정보의 어느 부분이 사용되는지(값 기반 vs 구조 기반), (ii) 새로운 데이터를 생성하기 위해 얼마나 많은 샘플을 사용하는지(샘플 수준, 쌍별, 모집단)로 분류.
- Populational augmentation에서 Vanilla(값/구조)와 Exogenous 생성의 차이점 구별.
- 다섯 가지 모달리티에 TAXONOMY를 적용하고 모달리티별 대표적 기법을 검토.
- 모달리티 간 핵심 경향 및 최신 문헌을 요약.
실험 결과
연구 질문
- RQ1RQ1: 각 새로운 샘플을 생성하는 데 얼마나 많은 샘플이 사용되는가(개체, 다수, 모집단).
- RQ2RQ2: 새로운 데이터를 생성하는 데 어떤 정보 부분이 사용되는가(값 기반 vs 구조 기반).
- RQ3RQ3: 모달리티 독립적 TAXONOMY가 서로 다른 데이터 유형 간의 공통 패턴을 어떻게 밝힐 수 있는가.
- RQ4RQ4: 이미지, 텍스트, 그래프, 표, 시계열 전반의 최신 데이터 증강 방법이 제안된 TAXONOMY에 어떻게 부합하는가.
주요 결과
- 논문은 다섯 가지 데이터 모달리티에 적용 가능한 모달리티 독립적이고 데이터 중심적인 TAXONOMY를 제공합니다.
- 분류를 위한 세 가지 증강 유형(개체, 다수, 모집단)과 두 정보 원천(값 vs 구조)을 식별합니다.
- 이미지, 텍스트, 그래프, 표, 시계열 모달리티 전반의 최신 데이터 증강 문헌을 통합하고 분류합니다.
- 각 모달리티에서 정보를 증강에 활용하는 방법에 대해 통일된 원칙을 통해 강조합니다.
- 자동 정책 검색 및 mixup 기반 전략을 포함한 최신 기법들을 제시된 프레임워크 내에서 조사하고 종합합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.