[논문 리뷰] A Context-Aware Citation Recommendation Model with BERT and Graph Convolutional Networks
이 논문은 문맥 텍스트 인코딩을 위한 BERT와 인용 관계를 모델링하기 위한 그래프 컬러션 네트워크(GCN)를 사용하는 문맥 인식 인용 추천 모델을 제안한다. 이는 평균 평균 정밀도(MAP)와 리콜@k에서 기존 방법보다 28% 향상된 최신 기술 수준의 성능을 달성한다. 또한, 인용 추천을 위한 표준화된 벤치마크 데이터셋인 FullTextPeerRead를 소개한다. 이 데이터셋은 문맥 문장과 논문 메타데이터를 결합한 첫 번째 잘 정리된 데이터셋이다.
With the tremendous growth in the number of scientific papers being published, searching for references while writing a scientific paper is a time-consuming process. A technique that could add a reference citation at the appropriate place in a sentence will be beneficial. In this perspective, context-aware citation recommendation has been researched upon for around two decades. Many researchers have utilized the text data called the context sentence, which surrounds the citation tag, and the metadata of the target paper to find the appropriate cited research. However, the lack of well-organized benchmarking datasets and no model that can attain high performance has made the research difficult. In this paper, we propose a deep learning based model and well-organized dataset for context-aware paper citation recommendation. Our model comprises a document encoder and a context encoder, which uses Graph Convolutional Networks (GCN) layer and Bidirectional Encoder Representations from Transformers (BERT), which is a pre-trained model of textual data. By modifying the related PeerRead dataset, we propose a new dataset called FullTextPeerRead containing context sentences to cited references and paper metadata. To the best of our knowledge, This dataset is the first well-organized dataset for context-aware paper recommendation. The results indicate that the proposed model with the proposed datasets can attain state-of-the-art performance and achieve a more than 28% improvement in mean average precision (MAP) and recall@k.
연구 동기 및 목표
- 문맥 인식 인용 추천을 위한 표준화된 벤치마크 데이터셋의 부족으로 인해 재현 가능성이 떨어지고 모델 평가가 어렵다는 문제를 해결하기 위해.
- BERT를 통한 문맥 텍스트 이해와 GCN를 통한 구조적 인용 네트워크 모델링을 통합하여 인용 추천 성능을 향상시키기 위해.
- 문맥 문장, 참조 메타데이터, 그리고 과학 논문의 인용 링크를 포함한 재현 가능한, 잘 정리된 데이터셋인 FullTextPeerRead를 개발하기 위해.
- 문맥 길이와 인용 빈도가 인용 추천 작업에서 모델 성능에 미치는 영향을 조사하기 위해.
- MAP, MRR, 리콜@k 지표에서 기존 방법을 능가하는 새로운 최신 기술 수준의 모델을 제공하기 위해.
제안 방법
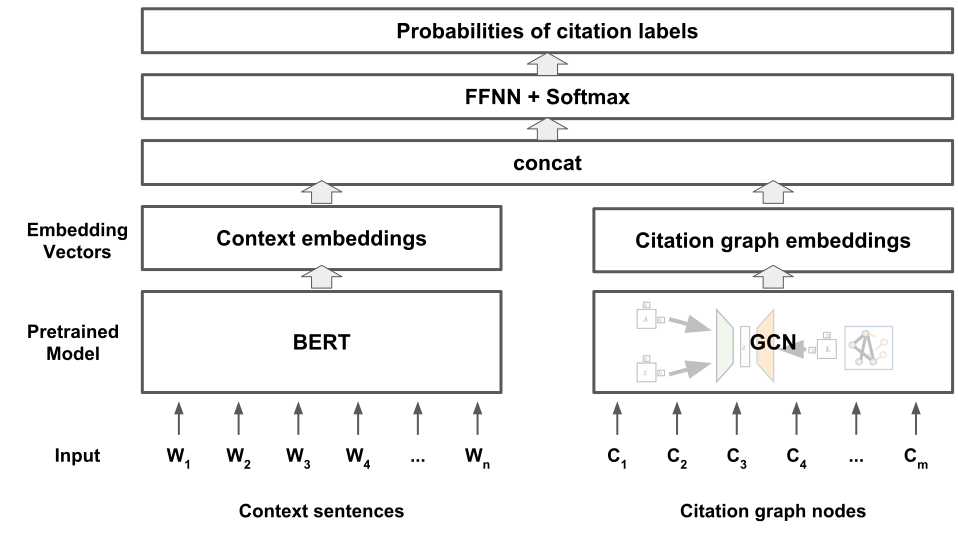
- 모델은 이중 인코더 아키텍처를 사용한다: 인용 플레이스홀더 주변의 문맥 텍스트를 인코딩하기 위한 BERT 기반의 문맥 인코더.
- 그래프 컬러션 네트워크(GCN) 레이어는 인용 네트워크 데이터를 처리하여 논문 인용 그래프로부터 잠재 표현을 학습한다.
- 변동형 그래프 오토인코더(VGAE)는 GCN 인코더를 정규화하고 국소적 문맥 패턴에 대한 과적합을 줄이기 위해 적용된다.
- 최종 표현은 BERT의 문맥 임베딩과 GCN의 그래프 기반 임베딩을 조합하여 후보 인용의 유사도 점수를 계산한다.
- FullTextPeerRead 데이터셋은 arXiv Vanity를 통해 LaTeX 기반 PDF를 파싱하여 문맥 문장과 메타데이터를 추출하고, PeerRead 및 AAN 데이터셋에 문맥 기반 인용 정보를 보완함으로써 구축된다.
- 모델은 대조 학습을 사용하여 엔드 투 엔드로 훈련되며, 관련 있는 인용을 추천 목록에서 높게 순위 매기기 위해 최적화된다.
실험 결과
연구 질문
- RQ1BERT와 GCN를 통합하는 것이 BERT만을 사용할 때보다 인용 추천 성능을 얼마나 향상시키는가?
- RQ2문맥 시퀀스의 길이가 인용 추천에서 모델 성능에 얼마나 영향을 미치는가?
- RQ3대상 논문의 인용 빈도가 모델이 정확하게 이를 추천하는 데 미치는 영향은 어떠한가?
- RQ4FullTextPeerRead와 같은 통합적이고 잘 정리된 데이터셋이 인용 추천 연구에서 일관된 벤치마킹과 재현 가능성을 가능하게 하는가?
- RQ5GCN를 통한 그래프 기반 인용 구조 모델링이 텍스트 기반 문맥만을 고려할 때보다 관련성 추정을 얼마나 향상시키는가?
주요 결과
- 제안된 BERT-GCN 모델은 기준 모델 대비 평균 평균 정밀도(MAP)와 리콜@k에서 28% 향상된 성능을 달성한다.
- GCN 통합이 있는 모델은 BERT만을 사용하는 모델보다 성능이 뛰어나며, 인용 빈도 5일 때 MAP가 0.6736으로, BERT 단독 모델의 0.6593보다 높다.
- 문맥 길이가 100 토큰을 초과하면 성능 향상 폭이 둔화되어, 특정 문맥 창 너비를 넘어서면 수익 감소 현상이 나타난다.
- 대상 논문의 인용 빈도가 높을수록 모델 성능이 향상되며, 이는 빈번한 인용이 더 신뢰할 수 있는 학습 신호를 제공하기 때문으로 보인다.
- FullTextPeerRead 데이터셋은 정확하고 일관된 문맥 추출을 가능하게 하며, 실제 과학 논문에서 유래한 잘 정리된 메타데이터와 문맥 문장을 포함한다.
- GCN는 인용 네트워크의 구조를 포착하여, 단순 텍스트 기반 임베딩만으로는 불가능한 성능 향상을 이룬다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.