QUICK REVIEW
[논문 리뷰] A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong|arXiv (Cornell University)|2023. 10. 14.
Advanced Text Analysis Techniques인용 수 41
한 줄 요약
TimesFM은 실제 데이터와 합성 데이터로 사전 학습된 디코더 전용 시계열 기반 모델로, 도메인 간 미지의 데이터세트에 대해 거의 최첨단의 제로샷 예측 성능을 달성합니다.
ABSTRACT
Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.
연구 동기 및 목표
- 다양한 데이터세트에 대해 도메인별 공변량(dataset-specific covariates) 없이 일반적인 제로샷 예측모형을 구축하는 동기 부여.
- 입력 패치를 사용하는 디코더 스타일 트랜스포머를 설계하여 다양한 컨텍스트와 수평 길이에 적합하도록.
- 약 100B 시점의 시간포인트에서 교육된 200M 매개변수 모델이 보지 않은 데이터에서 감독-상태 정확도에 근접할 수 있음을 보여준다.
- 다양한 도메인, 세분성, 수평에 대한 제로샷 성능을 시연한다.
- 아키텍처 선택과 사전 학습 데이터의 영향력을 정당화하기 위한 ablation 연구를 제공한다.
제안 방법
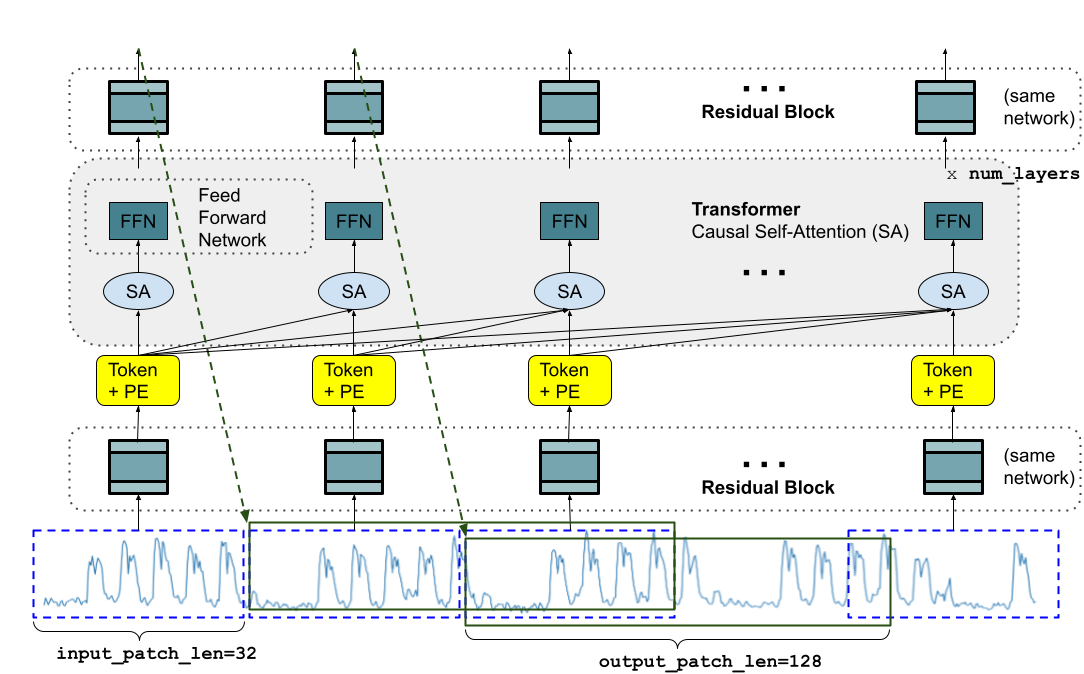
- 시간 시계열을 패치로 변환하고 디코더 전용 트랜스포머에 입력으로 제공하기 위한 패치 기반 입력 처리.
- 더 긴 출력 패치를 사용하여 더 긴 수평을 예측하고 자기회귀(step)를 줄인다.
- 훈련 중 패치 마스킹을 적용하여 1에서 최대 컨텍스트 길이까지 가변 컨텍스트 길이를 가능하게 한다.
- 잉여 블록과 인과적 다중 헤드 자기 주의를 갖춘 디코더 전용 모델(TimesFM)을 훈련한다.
- 실제 세계(Google Trends, Wiki Pageviews)와 합성 시계열의 큰 혼합 코퍼스로 프리트레이닝한다(~100B timepoints).
- 점 예측에 대해 MSE 손실로 학습하며, 향후 확률적 헤드의 가능성을 남겨 둔다.
실험 결과
연구 질문
- RQ1하나의 사전 학습된 시계열 기반 모델이 다양한 도메인에 걸쳐 미지의 데이터셋에 대해 강력한 제로샷 예측을 달성할 수 있는가?
- RQ2패치 구성, 디코더 전용 설계, 패치 길이의 트레이드오프 등 어떤 아키텍처 선택이 시계열 예측에서 효과적인 제로샷 일반화를 가능하게 하는가?
- RQ3데이터 소스와 사전 학습 규모가 다양한 수평과 세분성에 걸친 제로샷 예측 성능에 어떤 영향을 미치는가?
- RQ4기초 모델 설정에서 긴 수평 예측을 위한 더 긴 출력 패치 디코딩이 이로운가?
- RQ5패치 크기와 마스킹 전략이 컨텍스트 길이의 강건성과 정확도에 미치는 영향은 무엇인가?
주요 결과
- TimesFM은 다양한, 아직 보지 못한 데이터세트에서 감독 학습 모델과의 제로샷 예측 성능이 거의 근접하다.
- 200M 매개변수의 모델이 ~100B timepoints에서 프리트레이닝되면 서로 다른 수평 및 세분성에 걸쳐 일반화할 수 있다.
- TimesFM은 제로샷 설정에서 Monash, Darts, 및 Informer 데이터셋 그룹에서 상위 기준선과 경쟁력이 있다.
- ABLATIONS은 매개변수 스케일링이 성능을 향상시키고, 더 긴 출력 패치는 자동회귀 스텝 수를 줄이며 긴 수평에 대한 정확도를 향상시킨다.
- 대규모의 다양한 사전 학습 데이터(실제 + 합성)가 실제 데이터만 학습한 경우에 비해 제로샷 성능을 크게 향상시킨다.
![(a) Monash Archive [ 8 ]](https://ar5iv.labs.arxiv.org/html/2310.10688/assets/monash_mae_chart_200m.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.