[논문 리뷰] A Practical Mixed Precision Algorithm for Post-Training Quantization
논문은 훈련 데이터 없이도 AdaRound 통합을 통해 저비트 성능을 향상시키고, SQNR에 기반한 각 층 민감도 리스트를 구성한 후 Pareto-frontier 탐욕적 탐색으로 하드웨어 및 정확도 예산 내에서 비트너비를 할당하는 사후 학습 혼합 정밀도 양자화 방법을 제시한다.
Neural network quantization is frequently used to optimize model size, latency and power consumption for on-device deployment of neural networks. In many cases, a target bit-width is set for an entire network, meaning every layer get quantized to the same number of bits. However, for many networks some layers are significantly more robust to quantization noise than others, leaving an important axis of improvement unused. As many hardware solutions provide multiple different bit-width settings, mixed-precision quantization has emerged as a promising solution to find a better performance-efficiency trade-off than homogeneous quantization. However, most existing mixed precision algorithms are rather difficult to use for practitioners as they require access to the training data, have many hyper-parameters to tune or even depend on end-to-end retraining of the entire model. In this work, we present a simple post-training mixed precision algorithm that only requires a small unlabeled calibration dataset to automatically select suitable bit-widths for each layer for desirable on-device performance. Our algorithm requires no hyper-parameter tuning, is robust to data variation and takes into account practical hardware deployment constraints making it a great candidate for practical use. We experimentally validate our proposed method on several computer vision tasks, natural language processing tasks and many different networks, and show that we can find mixed precision networks that provide a better trade-off between accuracy and efficiency than their homogeneous bit-width equivalents.
연구 동기 및 목표
- 균일한 비트폭이 아닌 계층별 양자화에 대한 강건성을 활용하여 온-디바이스 성능을 향상시키려는 동기를 제시한다.
- 최소한의 데이터와 하이퍼파라미터 튜닝 없이도 가능한 사후 학습 양자화 방법을 개발한다.
- 양자화 그룹 및 효율성 지표를 통해 실제 하드웨어 제약을 반영한다.
- 보정 데이터의 변화 및 도메인 외 입력에 대한 강건성을 입증한다.
- 제안된 방법이 다양한 모델에서 균일 양자화보다 더 나은 정확도-효율성 트레이드오프를 산출함을 보여준다.
제안 방법
- 1단계는 각 층에 대해 서로 다른 양자화 옵션으로 네트워크 손실을 측정하여 계층별 민감도 목록을 생성하고, 민감도 지표로 SQNR을 사용한다.
- 2단계는 가장 높은 정밀도의 양자화에서 시작하여 민감도 목록에 의해 안내되며, Pareto 프런티어 탐욕적 탐색을 통해 미리 정의된 성능 예산을 달성하기 위해 비트폭을 순차적으로 낮춘다.
- 공유된 연산이 그룹 전체에서 일관된 정밀도를 사용하도록 하드웨어 의존성을 강제하기 위해 양자화 그룹이 도입된다.
- AdaRound를 통합하여 1단계 민감도 측정에서 AdaRounded 가중치를 사용하고, 이후 비트폭 구성 간에 이 가중치를 이어붙여 저비트 양자화 성능을 향상시킨다.
- 탐색은 이진 탐색과 보간 전략을 사용하여 실행 시간을 줄이면서 단조로운 Pareto 곡선을 활용해 가속화할 수 있다.
- 1단계는 라벨 없이 작동하고, 제한된 보정 데이터에 견딜 수 있으며 데이터 변동에 견고하게 남아 있다.
실험 결과
연구 질문
- RQ1CV 및 NLP 작업에서 다양한 아키텍처에 대해 사후 학습 혼합 정밀도 양자화가 고정 정밀도 양자화를 능가할 수 있는가?
- RQ2보정 데이터의 변동과 도메인 외 데이터를 민감도 추정에 사용하는 경우의 강건성은 얼마나 되는가?
- RQ3양자화 그룹화 등 하드웨어 제약이 가능한 혼합 정밀도 구성과 성능에 어떤 영향을 미치는가?
- RQ4AdaRound를 혼합 정밀도 파이프라인에 통합하는 것이 특히 매우 낮은 비트폭에서 정확도를 향상시키는가?
주요 결과
- 제안된 PTQ MP 방법은 Mobilenetv3, Deeplabv3, Efficientnet, BERT, ViT 등을 포함한 여러 모델에서 균일 비트폭 네트워크보다 더 나은 정확도-효율성 트레이드오프를 제공하는 혼합 정밀도 구성을 찾는다.
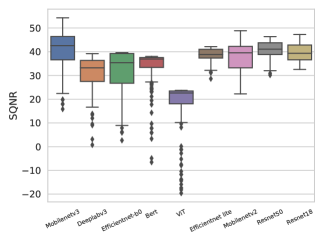
- SQNR 기반의 계층별 민감도 목록은 보정 데이터 변동과 보정 이미지 수에 대한 강건성을 보이며, 정확도 기반 민감도에 비해 유리한 Kendall Tau 상관관계를 보인다.
- AdaRound를 혼합 정밀도 파이프라인에 통합하면 저비트(8 미만) 양자화 성능이 향상되고 고정 정밀도 AdaRound를 능가할 수 있다.
- 2단계의 런타임은 이진 탐색 및 보간 전략으로 개선되어 검색 복잡도를 줄이면서도 좋은 Pareto 곡선을 유지한다.
- 다양한 비트폭 후보 세트(W4A8, W8A8, W8A16 등)와 확장된 저비트 공간(W4A4, W6A6 등)에서도 방법이 여전히 효과적이다.
- 1단계 및 2단계는 적은 양의 데이터 또는 전혀 없는 작업 데이터로도 작동하므로 도메인 외 또는 프라이버시 보존 보정 시나리오를 가능하게 한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.