[논문 리뷰] A Survey of Deep Learning and Foundation Models for Time Series Forecasting
시계열 예측을 위한 심층 학습, 트랜스포머, 파운데이션 모델 및 지식 기반 접근법에 대한 포괄적 조사로, 팬데믹 예측 및 지식 그래프, LLM, 사전 학습의 통합에 초점을 맞춤.
Deep Learning has been successfully applied to many application domains, yet its advantages have been slow to emerge for time series forecasting. For example, in the well-known Makridakis (M) Competitions, hybrids of traditional statistical or machine learning techniques have only recently become the top performers. With the recent architectural advances in deep learning being applied to time series forecasting (e.g., encoder-decoders with attention, transformers, and graph neural networks), deep learning has begun to show significant advantages. Still, in the area of pandemic prediction, there remain challenges for deep learning models: the time series is not long enough for effective training, unawareness of accumulated scientific knowledge, and interpretability of the model. To this end, the development of foundation models (large deep learning models with extensive pre-training) allows models to understand patterns and acquire knowledge that can be applied to new related problems before extensive training data becomes available. Furthermore, there is a vast amount of knowledge available that deep learning models can tap into, including Knowledge Graphs and Large Language Models fine-tuned with scientific domain knowledge. There is ongoing research examining how to utilize or inject such knowledge into deep learning models. In this survey, several state-of-the-art modeling techniques are reviewed, and suggestions for further work are provided.
연구 동기 및 목표
- 고전 통계에서 딥러닝 및 파운데이션 모델에 이르기까지 시계열 예측 방법의 진행을 평가한다.
- 인코더-디코더, 트랜스포머, 그래프 신경망 아키텍처가 시계열에서 시간적 및 공간적 의존성을 어떻게 포착하는지 검토한다.
- 지식 그래프 및 대형 언어 모델과 같은 지식 소스가 예측 모델을 보강하는 방법을 탐구한다.
- 팬데믹 예측의 도전 과제와 이론 주도 데이터 사이언스 및 물리 정보 기반 접근의 기회를 밝힌다.
- 향후 연구 방향과 모델 개발 및 평가에 대한 실용적 권고를 제시한다.
제안 방법
- SARIMAX, VAR, LSTM/GRU, 인코더-디코더 및 트랜스포머 기반 접근 방식을 포함하여 과거 및 현재의 시계열 예측 모델을 조사한다.
- 다변량 시계열에 대한 희소 어텐션, 패치 기반 트랜스포머 및 사전 학습/MAE 기술의 발전을 논의한다.
- 표현 학습 방법(TS2Vec, CoST, FEAT, SimTS 등)과 이들의 예측 성능 및 해석 가능성에 대한 영향을 검토한다.
- 공간-시간 예측을 위한 그래프 신경망의 역할을 요약하고, 특히 팬데믹 데이터의 국가 및 주 차원의 데이터를 다룬다.
- 예측 품질, 설명 가능성 및 과학적 기초를 향상시키기 위한 지식 소스(지식 그래프, LLMs)의 사용을 강조한다.
- 현재 문헌에서 다양한 모델링 기술의 효과성에 대한 메타 연구 관점을 제시한다.
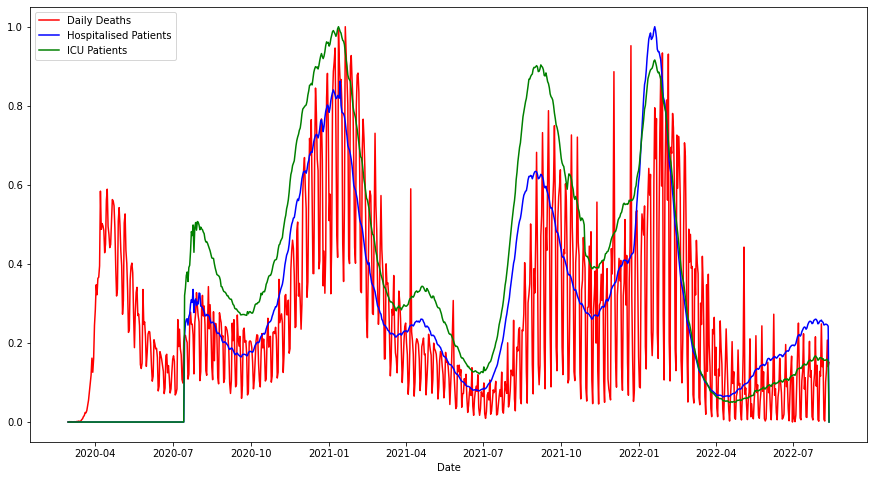
실험 결과
연구 질문
- RQ1무슨 모델링 기법들이 시계열 예측의 개선을 주도하고 있으며, 그것들이 전통적 기준선과 어떻게 비교되는가?
- RQ2트랜스포머 기반 및 그래프 기반 아키텍처가 시간적 및 공간적 예측 작업, 팬데믹 데이터를 포함하여 어떻게 수행되는가?
- RQ3사전 학습, 패칭, 표현 학습이 예측 정확도와 효율성을 향상시키는 데 어떤 역할을 하는가?
- RQ4지식 그래프와 대형 언어 모델을 예측 품질과 해석 가능성을 높이기 위해 어떻게 통합할 수 있는가?
- RQ5시계열 예측에서 파운데이션 모델의 주요 도전 과제와 향후 방향은 무엇인가?
주요 결과
- 트랜스포머 및 관련 주의 기반 아키텍처가 시계열 예측에서 최상위 성능으로 부상했으며, 특히 시간적 동적에 대해 강력한 성능을 보인다.
- 희소 어텐션, 패치 기반 입력 및 자동상관 기술이 계산 비용을 줄이고 트랜스포머를 이용한 장기 예측 성능을 향상시킬 수 있다.
- 표현 학습 접근법(TS2Vec, CoST, FEAT, SimTS 등)은 예측을 지원하는 효과적인 잠재 표현을 제공하고 해석 가능성을 개선할 수 있다.
- 그래프 신경망은 공간-시간 의존성을 포착하는 데 잘 맞으며, 특히 주·국가 수준의 팬데믹 데이터에 적합하다.
- 사전 학습 및 지식 그래프와 LLM의 활용을 포함한 파운데이션 모델 아이디어는 팬데믹 대비 및 설명 가능성을 개선할 가능성을 시사하지만, 짧은 시계열 및 분포 변화 등의 과제가 남아 있다.
- 메타 연구 관점은 현재 문헌에서 다양한 기법의 효과가 다르게 나타나며, ML 기반 방법이 최근에는 고전적 통계적 접근법과 경쟁하거나 이를 능가하는 경향을 보인다.
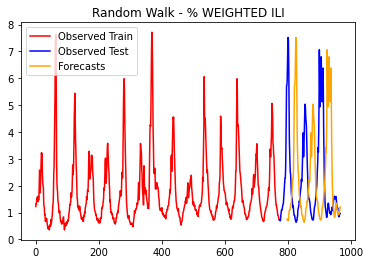
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.