[논문 리뷰] A Survey of Safety and Trustworthiness of Large Language Models through the Lens of Verification and Validation
본 논문은 LLM의 안전성 및 신뢰성 취약점을 검토하고 V&V 기법이 LLM 생애주기에 걸쳐 어떻게 적용될 수 있는지 조사하며, 위조/검증, 검증, 런타임 모니터링, 그리고 윤리/규제 고려를 포함하는 프레임워크를 제안한다.
Large Language Models (LLMs) have exploded a new heatwave of AI for their ability to engage end-users in human-level conversations with detailed and articulate answers across many knowledge domains. In response to their fast adoption in many industrial applications, this survey concerns their safety and trustworthiness. First, we review known vulnerabilities and limitations of the LLMs, categorising them into inherent issues, attacks, and unintended bugs. Then, we consider if and how the Verification and Validation (V&V) techniques, which have been widely developed for traditional software and deep learning models such as convolutional neural networks as independent processes to check the alignment of their implementations against the specifications, can be integrated and further extended throughout the lifecycle of the LLMs to provide rigorous analysis to the safety and trustworthiness of LLMs and their applications. Specifically, we consider four complementary techniques: falsification and evaluation, verification, runtime monitoring, and regulations and ethical use. In total, 370+ references are considered to support the quick understanding of the safety and trustworthiness issues from the perspective of V&V. While intensive research has been conducted to identify the safety and trustworthiness issues, rigorous yet practical methods are called for to ensure the alignment of LLMs with safety and trustworthiness requirements.
연구 동기 및 목표
- LLMs의 안전성 및 신뢰성 취약점을 식별하고 분류합니다(본질적인 문제, 공격, 의도치 않은 버그).
- 엄격한 안전성 분석을 위해 LLM 생애주기에 V&V 기법을 통합하는 방법을 탐구합니다.
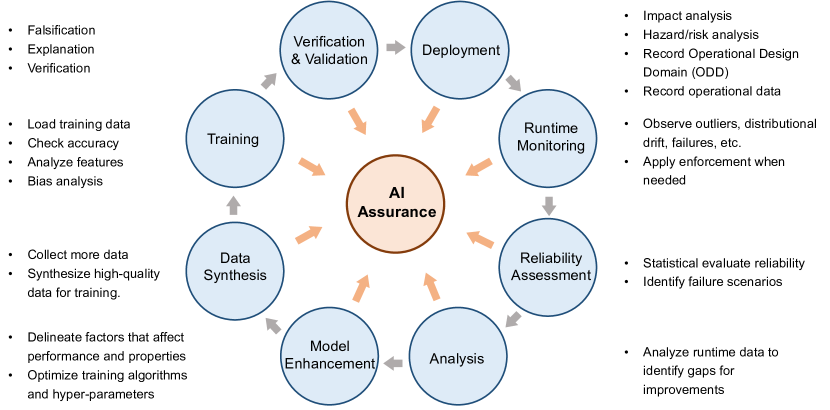
- AI 보장을 지원하기 위한 위조/평가, 검증, 런타임 모니터링, 윤리/규제 등을 포함하는 프레임워크를 제시합니다.
- LLM 개발 및 배치에서 핵심 안전 메커니즘으로 RLHF와 가드레일(가드레일)을 논의합니다.
제안 방법
- 알려진 LLM 취약점을 검토하고 분류합니다(본질적 문제, 공격, 의도치 않은 버그).
- V&V 기법(위조, 검증, 런타임 모니터링)의 LLM 생애주기 전반에 대한 적용 가능성을 분석합니다.
- 문헌(370편 이상)을 종합하여 V&V 기법을 안전성 및 신뢰성 목표에 연결합니다.
- LLMs 및 AI 보장을 위해 맞춤화된 보완적 V&V 프레임워크를 제안합니다.
실험 결과
연구 질문
- RQ1LLM의 생애주기 전반에서 주요한 안전성 및 신뢰성 취약점은 무엇인가?
- RQ2전통적인 V&V 기법을 실제로 LLM을 검증하고 검증하는 데 어떻게 확장하거나 적용할 수 있는가?
- RQ3RLHF와 가드레일이 안전 요구사항에 맞추어 LLM을 정렬하는 데 어떤 역할을 하는가?
- RQ4기존 벤치마크, 모니터링 전략 및 규제 고려사항이 LLM 안전성에 대해 어떤 지침을 제공하는가?
- RQ5취약점 식별과 실용적 검증/평가 방법 사이에 남은 격차는 무엇인가?
주요 결과
- LLM은 안전성 및 신뢰성에 영향을 미치는 고유한 성능 및 지속가능성 문제를 나타낸다.
- 공격(개인정보 누출, 백도어, 오염, 허위정보) 및 의도치 않은 버그는 배치 중 추가 위험을 제기한다.
- LLM의 비결정성 및 규모를 고려할 때 블랙박스 V&V와 런타임 모니터링은 필수적이며 확장 가능하고 실용적인 평가 방법이 필요하다.
- RLHF와 가드레일은 현재 안전 전략의 핵심이지만 도움성과 무해성 사이의 균형 트레이드오프를 야기할 수 있다.
- 생애주기 단계 전반에 걸쳐 안전성 및 신뢰성 요건과의 정렬을 보장하기 위한 엄격하면서도 실용적인 V&V 방법이 강하게 필요하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.