[논문 리뷰] A Survey on Large Language Models for Critical Societal Domains: Finance, Healthcare, and Law
이 설문은 큰 언어 모델(LLMs)이 금융, 보건의료 및 법률에서 어떻게 적용되는지 분석하고, 성능을 평가하며, 도전 과제와 윤리를 논의하고, 도메인별 작업, 데이터 세트, 멀티모달 고려사항에 초점을 맞춘 향후 방향을 제시합니다.
In the fast-evolving domain of artificial intelligence, large language models (LLMs) such as GPT-3 and GPT-4 are revolutionizing the landscapes of finance, healthcare, and law: domains characterized by their reliance on professional expertise, challenging data acquisition, high-stakes, and stringent regulatory compliance. This survey offers a detailed exploration of the methodologies, applications, challenges, and forward-looking opportunities of LLMs within these high-stakes sectors. We highlight the instrumental role of LLMs in enhancing diagnostic and treatment methodologies in healthcare, innovating financial analytics, and refining legal interpretation and compliance strategies. Moreover, we critically examine the ethics for LLM applications in these fields, pointing out the existing ethical concerns and the need for transparent, fair, and robust AI systems that respect regulatory norms. By presenting a thorough review of current literature and practical applications, we showcase the transformative impact of LLMs, and outline the imperative for interdisciplinary cooperation, methodological advancements, and ethical vigilance. Through this lens, we aim to spark dialogue and inspire future research dedicated to maximizing the benefits of LLMs while mitigating their risks in these precision-dependent sectors. To facilitate future research on LLMs in these critical societal domains, we also initiate a reading list that tracks the latest advancements under this topic, which will be continually updated: \url{https://github.com/czyssrs/LLM_X_papers}.
연구 동기 및 목표
- 고객 데이터의 민감성과 규제 준수가 중요한 고위험 도메인에서 LLM 연구를 추진합니다.
- 금융, 보건의료 및 법률 NLP 작업, 데이터 세트 및 LLM을 조사하여 강점, 격차 및 향후 연구 방향을 식별합니다.
- 윤리적 고려사항, 도메인별 요구사항(규제, 설명가능성, 공정성) 및 학제간 협력의 필요성을 강조합니다.
제안 방법
- 기존 금융 NLP 작업 및 데이터 세트(SA, IE, QA, SMP, 등)를 카탈로그하고 데이터 세트와 벤치마크를 주목합니다.
- 금융 LLM, 사전 학습 대 지시-튜닝 방식의 비교 및 작업 간 평가 결과를 요약합니다.
- 멀티모달 또는 구조화된 데이터에 주목하여 보건의료 및 법률 NLP 작업, LLM 및 평가 방법론을 조사합니다.
- LLM 배치에 대한 윤리, 도메인별 우려 및 규제 고려사항을 논의합니다.
- 향후 연구를 안내하기 위한 도메인 간 도전과 기회의 교차 도합을 제공합니다.
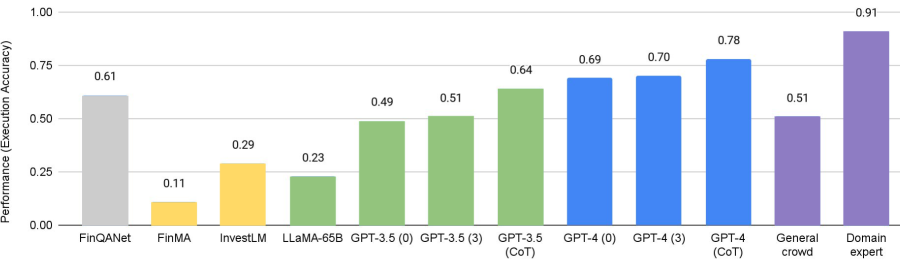
실험 결과
연구 질문
- RQ1금융, 보건의료 및 법률에서 LLM을 평가하는 데 사용되는 주요 NLP 작업과 벤치마크는 무엇입니까?
- RQ2표준 작업 및 데이터 세트에서 금융, 보건의료 및 법률 LLM의 성능 차이는 어떠합니까?
- RQ3이들 도메인에서 LLM 능력을 형성하는 주요 방법론적 접근(사전 학습 vs 지시-튜닝, 멀티모달 통합)은 무엇입니까?
- RQ4이들 분야에서 LLM 채택을 지배하는 윤리적, 규제적, 투명성 문제는 무엇이며 어떻게 완화할 수 있습니까?
주요 결과
| 모델 | FPB | FiQA-SA | 헤드라인 | NER FIN3 | Entity F-1 |
|---|---|---|---|---|---|
| Fine-tuning | 0.86 | 0.84 | 0.87 | 0.95 | 0.83 |
| BloombergGPT (few-shot) | - | 0.51 | 0.75 | 0.82 | 0.61 |
| LlaMA-65B (zero-shot) | - | 0.38 | 0.75 | - | - |
| InvestLM (zero-shot) | - | 0.71 | 0.90 | - | - |
| FinMA-30B (zero-shot) | 0.87 | 0.88 | 0.87 | 0.97 | 0.62 |
| GPT-3.5 (zero-shot) | 0.78 | 0.78 | 0.76 | 0.72 | 0.29 |
| GPT-3.5 (few-shot) | 0.79 | 0.79 | 0.78 | 0.75 | 0.52 |
| GPT-4 (zero-shot) | 0.83 | 0.83 | 0.87 | 0.84 | 0.36 |
| GPT-4 (few-shot) | 0.86 | 0.86 | 0.88 | 0.86 | 0.57 |
- LLMs는 분석, 해석 및 의사 결정 지원을 강화하기 위해 금융, 보건의료 및 법률 전반에서 점점 더 많이 사용되고 있지만, 작업 및 모달리티에 따라 성능이 달라집니다.
- 금융에서 특화된 LLM(예: BloombergGPT, FinMA variants, InvestLM)은 감정 분석, QA 및 정보 추출에서 개선을 보이나 멀티모달 및 수치적 추론은 여전히 도전적입니다.
- 보건의료 응용은 의학 NLP, 이상 징후 탐지, 의무 보고서 생성 및 영상-언어 작업 등을 망라하며, 임상 맥락에서의 지시 준수 및 평가에 대한 관심이 증가하고 있습니다.
- 법률 중심 LLM은 계약 분석, 법령 해석, 판례 QA 등의 작업에서 발전하고 있으며, 고위험 법률 환경에서의 해석 가능성과 신뢰성에 중점을 두고 있습니다.
- 윤리적 고려사항—개인정보 보호, 데이터 보안, 편향, 설명가능성 및 규제 준수—은 세 도메인 모두에서 핵심이며, 투명하고 공정하며 감사 가능한 AI 시스템이 필요합니다.
- 조사된 문헌은 소규모 도메인 미세조정에서 더 큰 지시-튜닝 및 다국어/멀티모달 LLM으로의 추세를 강조하며, 더 나은 평가 기준과 데이터 거버넌스에 대한 요구를 제시합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.