[논문 리뷰] A Survey on Speech Deepfake Detection
본 조사는 TTS 및 VC로 생성된 음성 딥페이크에 대한 오디오 안티스푸핑 탐지에 대해 다루며, 아키텍처, 데이터셋, 지표, 최적화 기법, 오픈소스 리소스를 포함하고, 도전과제 및 향후 방향에 대한 논의를 제공합니다.
The availability of smart devices leads to an exponential increase in multimedia content. However, advancements in deep learning have also enabled the creation of highly sophisticated Deepfake content, including speech Deepfakes, which pose a serious threat by generating realistic voices and spreading misinformation. To combat this, numerous challenges have been organized to advance speech Deepfake detection techniques. In this survey, we systematically analyze more than 200 papers published up to March 2024. We provide a comprehensive review of each component in the detection pipeline, including model architectures, optimization techniques, generalizability, evaluation metrics, performance comparisons, available datasets, and open source availability. For each aspect, we assess recent progress and discuss ongoing challenges. In addition, we explore emerging topics such as partial Deepfake detection, cross-dataset evaluation, and defences against adversarial attacks, while suggesting promising research directions. This survey not only identifies the current state of the art to establish strong baselines for future experiments but also offers clear guidance for researchers aiming to enhance speech Deepfake detection systems.
연구 동기 및 목표
- 완전 스푸프와 부분 스푸프를 포함한 스푸프된 음성을 정의하고 분류한다.
- 오디오 안티스푸핑 탐지 파이프라인과 그 구성 요소에 대한 포괄적 검토를 제공한다.
- 오디오 스푸핑 탐지에 사용되는 데이터셋, 평가 지표 및 벤치마킹 관행을 평가한다.
- 훈련 최적화 기법(데이터 증강, 손실 함수, 활성화 함수)을 분석하고 성능에 미치는 영향을 평가한다.
- 부분 스푸핑, 교차 데이터셋 평가, 적대적 방어 등 신흥 연구 주제와 오픈소스 이용 가능성에 대해 논의한다.
제안 방법
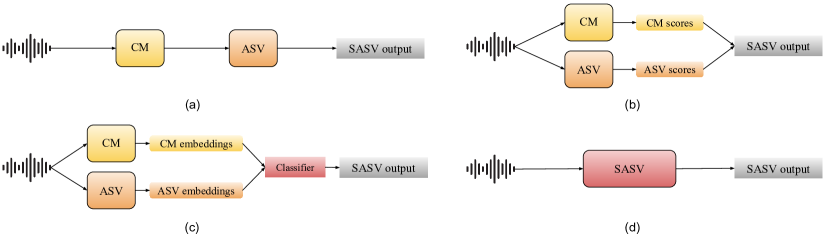
- 전면 특징 추출에서 백엔드 분류기 및 엔드투엔드 모델에 이르는 탐지 아키텍처의 체계적 검토.
- 특징 추출 접근법을 수작업으로 설계된 스펙트럼 특징, 딥러닝 특징, 분석 지향 특징으로 분류한다.
- 완전 스푸핑된 데이터와 부분적으로 스푸핑된 데이터 및 실제 데이터셋을 포함하여 오디오 안티스푸핑에 사용되는 데이터셋과 지표를 평가한다.
- 모델 성능에 미치는 영향을 포함한 학습 최적화 기법의 평가.
- 재현 가능한 연구를 가능하게 하는 오픈소스 리소스 및 벤치마킹 관행에 대한 논의.
- 현 분야의 도전과제와 향후 방향의 식별.

실험 결과
연구 질문
- RQ1완전 스푸프된 음성(TTS/VC)과 부분적으로 스푸프된 구간에서 강력한 탐지를 보장하는 아키텍처와 특징은 무엇인가?
- RQ2데이터셋, 보이지 않는 공격, 코덱이 벤치마크 전반의 일반화 및 평가 지표에 어떤 영향을 미치는가?
- RQ3훈련 기법(데이터 증강, 손실 함수, 활성화 선택)이 탐지 성능에 미치는 영향은 무엇인가?
- RQ4부분 스푸핑, 교차 데이터셋 전이, 적대적 방어 등 신흥 주제와 향후 연구를 이끄는 오픈소스 이용 가능성은 무엇인가?
주요 결과
- 본 고찰은 오디오 안티스푸핑에 대한 탐지 구성요소, 데이터셋, 지표 및 오픈소스 자원에 걸친 광범위한 스펙트럼을 다룬다.
- 데이터 증강, 활성화 함수, 손실 함수 등 모델 학습의 최적화 기법을 평가하고 성능에 미치는 영향을 논의한다.
- 완전 스푸핑 및 부분 스푸핑 시나리오, 교차 데이터셋 평가, 적대적 방어를 신흥 연구 주제로 강조한다.
- 재현 가능한 연구를 촉진하기 위한 SOTA 모델 및 벤치마킹 데이터셋에 대한 오픈소스 정보를 제공한다.
- SOTA 성능, 일반화 및 데이터셋 다양성에서의 현재 도전 과제를 식별하고 향후 연구 방향을 제시한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.