[논문 리뷰] Advancing Pose-Guided Image Synthesis with Progressive Conditional Diffusion Models
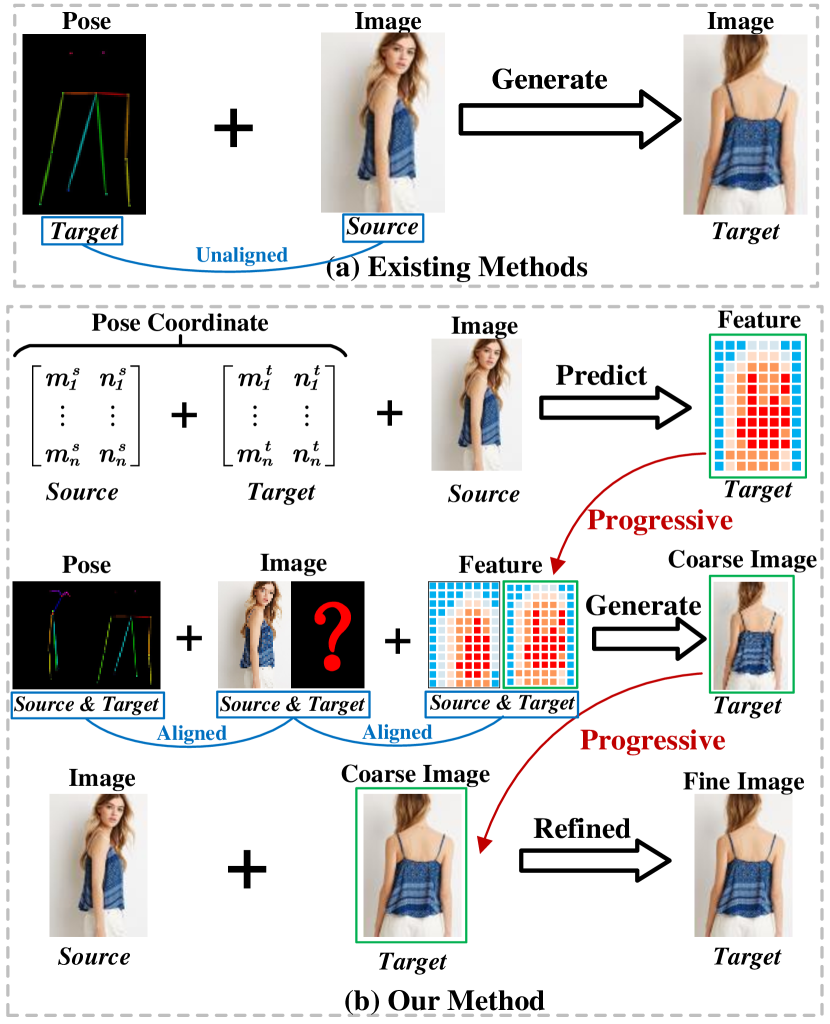
PCDMs는 소스 포즈와 타깃 포즈를 연결하기 위해 포즈 가이드를 받는 사람 이미지 합성에서 3단계 진행 Diffusion 프레임워크를 소개하며 현실감과 일관성을 향상시킵니다.
Recent work has showcased the significant potential of diffusion models in pose-guided person image synthesis. However, owing to the inconsistency in pose between the source and target images, synthesizing an image with a distinct pose, relying exclusively on the source image and target pose information, remains a formidable challenge. This paper presents Progressive Conditional Diffusion Models (PCDMs) that incrementally bridge the gap between person images under the target and source poses through three stages. Specifically, in the first stage, we design a simple prior conditional diffusion model that predicts the global features of the target image by mining the global alignment relationship between pose coordinates and image appearance. Then, the second stage establishes a dense correspondence between the source and target images using the global features from the previous stage, and an inpainting conditional diffusion model is proposed to further align and enhance the contextual features, generating a coarse-grained person image. In the third stage, we propose a refining conditional diffusion model to utilize the coarsely generated image from the previous stage as a condition, achieving texture restoration and enhancing fine-detail consistency. The three-stage PCDMs work progressively to generate the final high-quality and high-fidelity synthesized image. Both qualitative and quantitative results demonstrate the consistency and photorealism of our proposed PCDMs under challenging scenarios.The code and model will be available at https://github.com/tencent-ailab/PCDMs.
연구 동기 및 목표
- 소스 포즈와 타깃 포즈가 다를 때 포즈 가이드 사람 이미지 합성의 개선을 동기 부여합니다.
- appearance, pose, and texture를 점진적으로 맞추는 3단계 확산 프레임워크를 제안합니다.
- 전역 특징, 조밀 대응, 텍스처 정제를 활용하여 사진적 리얼리즘을 향상합니다.
- 공개 데이터셋에서 우수한 정량적 및 정성적 결과를 시연하고 다운스트림 애플리케이션을 평가합니다.
제안 방법
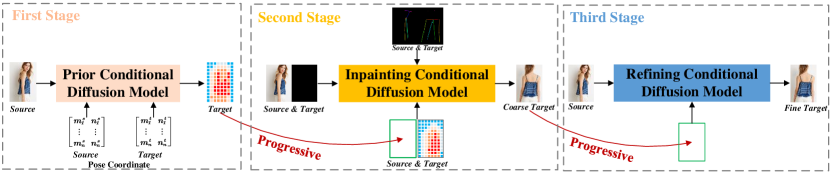
- Stage 1: Prior conditional diffusion model predicts the target image global features from pose coordinates and source image using a transformer and CLIP-based embeddings.
- Stage 2: Inpainting conditional diffusion model uses global target features to establish dense source-target correspondences and generate a coarse-skeleton image.
- Stage 3: Refining conditional diffusion model uses the coarse image to restore textures and fine details via texture-guided diffusion with cross-attention.
- Classifier-free guidance is employed to balance fidelity and diversity; latent diffusion and CLIP-based embeddings are leveraged.
- Three-stage progression converts unaligned input generation into aligned, high-quality synthesis.
실험 결과
연구 질문
- RQ1세 단계 진행 Diffusion 프레임워크가 소스 포즈와 타깃 포즈 사이의 차이를 효과적으로 brid ge하여 인물 이미지 합성을 가능하게 하나?
- RQ2전역 특징 예측, 조밀 대응, 텍스처 정제가 단일 단계 방식에 비해 개선을 가져오는가?
- RQ3PCDMs는 표준 벤치마크에서 어떻게 성능을 보이며 인물 재식별과 같은 다운스트림 작업에서 어떤 성능을 보이는가?
주요 결과
| Dataset | Methods | SSIM (↑) | LPIPS (↓) | FID (↓) |
|---|---|---|---|---|
| DeepFashion (256×176) | Def-GAN | 0.6786 | 0.2330 | 18.457 |
| DeepFashion (256×176) | PATN | 0.6709 | 0.2562 | 20.751 |
| DeepFashion (256×176) | ADGAN | 0.6721 | 0.2283 | 14.458 |
| DeepFashion (256×176) | PISE | 0.6629 | 0.2059 | 13.610 |
| DeepFashion (256×176) | GFLA | 0.7074 | 0.2341 | 10.573 |
| DeepFashion (256×176) | DPTN | 0.7112 | 0.1931 | 11.387 |
| DeepFashion (256×176) | CASD | 0.7248 | 0.1936 | 11.373 |
| DeepFashion (256×176) | NTED | 0.7182 | 0.1752 | 8.6838 |
| DeepFashion (256×176) | PIDM | 0.7312 | 0.1678 | 6.3671 |
| DeepFashion (256×176) | PCDMs (Ours) | 0.7444 | 0.1365 | 7.4734 |
| DeepFashion (512×352) | CocosNet2 | 0.7236 | 0.2265 | 13.325 |
| DeepFashion (512×352) | NTED | 0.7376 | 0.1980 | 7.7821 |
| DeepFashion (512×352) | PIDM | 0.7419 | 0.1768 | 5.8365 |
| DeepFashion (512×352) | PCDMs (Ours) | 0.7601 | 0.1475 | 7.5519 |
| Market-1501 | Def-GAN | 0.2683 | 0.2994 | 25.364 |
| Market-1501 | PTN | 0.2821 | 0.3196 | 22.657 |
| Market-1501 | GFLA | 0.2883 | 0.2817 | 19.751 |
| Market-1501 | DPTN | 0.2854 | 0.2711 | 18.995 |
| Market-1501 | PIDM | 0.3054 | 0.2415 | 14.451 |
| Market-1501 | PCDMs (Ours) | 0.3169 | 0.2238 | 13.897 |
- PCDMs는 DeepFashion 및 Market-1501에서 여러 SOTA 방법에 비해 더 높은 SSIM과 더 낮은 LPIPS를 달성합니다.
- DeepFashion 256x176에서 PCDMs는 SSIM 0.7444, LPIPS 0.1365, FID 7.4734로 다수의 베이스라인을 능가합니다.
- DeepFashion 512x352에서 PCDMs는 SSIM 0.7601, LPIPS 0.1475, FID 7.5519로 여러 경쟁자들을 앞섭니다.
- Market-1501에서 PCDMs는 SSIM 0.3169, LPIPS 0.2238, FID 13.897로 다수의 방법을 능가합니다.
- 사용자 연구에서 PCDMs에 대한 실제 이미지 오분류율 및 선호도 면에서 우호적인 결과가 나타납니다.
- 정제 확산은 다른 SOTA 방법에서도 결과를 향상시키며 보편성을 보여줍니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.