[논문 리뷰] Age Progression/Regression by Conditional Adversarial Autoencoder
이 논문은 쌍 샘플 없이도 연령 진행 및 회귀를 수행하기 위해 Conditional Adversarial Autoencoder (CAAE)를 제안한다. 이를 통해 사람 고유의 얼굴 매니폴드를 학습하고, 정체성을 유지하면서 연령에 따라 매니폴드를 탐색한다.
"If I provide you a face image of mine (without telling you the actual age when I took the picture) and a large amount of face images that I crawled (containing labeled faces of different ages but not necessarily paired), can you show me what I would look like when I am 80 or what I was like when I was 5?" The answer is probably a "No." Most existing face aging works attempt to learn the transformation between age groups and thus would require the paired samples as well as the labeled query image. In this paper, we look at the problem from a generative modeling perspective such that no paired samples is required. In addition, given an unlabeled image, the generative model can directly produce the image with desired age attribute. We propose a conditional adversarial autoencoder (CAAE) that learns a face manifold, traversing on which smooth age progression and regression can be realized simultaneously. In CAAE, the face is first mapped to a latent vector through a convolutional encoder, and then the vector is projected to the face manifold conditional on age through a deconvolutional generator. The latent vector preserves personalized face features (i.e., personality) and the age condition controls progression vs. regression. Two adversarial networks are imposed on the encoder and generator, respectively, forcing to generate more photo-realistic faces. Experimental results demonstrate the appealing performance and flexibility of the proposed framework by comparing with the state-of-the-art and ground truth.
연구 동기 및 목표
- 쿼리 이미지에서 쌍 데이터나 연령 레이블 없이 연령 진행/회귀를 유도한다.
- 개인별 identity를 보존하면서 노화를 부드럽게 탐색할 수 있는 얼굴 매니폴드를 학습한다.
- 성격(잠재 벡터 z)을 연령(레이블 l)로부터 분리하여 유연한 양방향 노화를 가능하게 한다.
- 생성된 얼굴이 사진 실제와 같고 자세, 표정, 가림에 강건하도록 한다.
제안 방법
- 인코더 E를 사용하여 개성을 보존하는 잠재 벡터 z로 얼굴을 인코드한다.
- 생성기 G를 연령 레이블 l로 조건부로 설정하여 G(z,l)로 z와 l에서 x^를 생성한다.
- z의 균일한 분포를 강제하기 위해 z-구분자 Dz를 도입하여 부드러운 노화 전이를 유도한다.
- 생성된 얼굴이 사진적으로 사실적이고 연령에 맞는 질감을 갖도록 이미지 구분자 Dimg를 도입한다.
- 입력 x와 노화 레이블 l이 있는 생성 x_hat 사이의 재구성 손실과 아티팩트 감소를 위한 TV 손실을 최소화한다.
- 대립적 목적과 L2/TV 손실을 사용하여 E, G, Dz, Dimg를 교대로 업데이트한다.
실험 결과
연구 질문
- RQ1쌍 데이터 없이도 연령 진행/회귀를 수행할 수 있는 얼굴 매니폴드를 학습할 수 있는가?
- RQ2성격(z)과 연령(l)을 분리하면 정체성을 유지하면서도 현실적이고 양방향 노화가 가능해지는가?
- RQ3z와 생성 이미지에 대한 이중 구분자들이 리얼리즘과 연령 조건 충실도를 향상시키는가?
- RQ4노화 과정에서 자세, 표정, 가림의 변화에도 강건한가?
- RQ5모형이 학습 분포를 넘어 그럴듯한 연령을 생성하고 정체성을 유지하는가?
주요 결과
- CAAE는 쌍 샘플에 의존하지 않고도 서로 다른 연령의 사진-realistic 얼굴 생성을 가능하게 한다.
- 잠재 벡터 z가 균일하게 분포되도록 장려되어 부드러운 연령 탐색이 가능하다.
- 이미지에 대한 구분자는 나이 들어 갈수록 질감이 좋고 적합한 텍스처를 만들어 노화의 현실감을 향상시킨다.
- 프레임워크는 노화 과정에서도 개성을 보존하며 자세, 표정, 가림에 대해 강건함을 보인다.
- 정성적 및 사용자 기반 평가에서 기존 연구들보다 더 높은 현실성 및 정체성 유지 성능을 보인다.
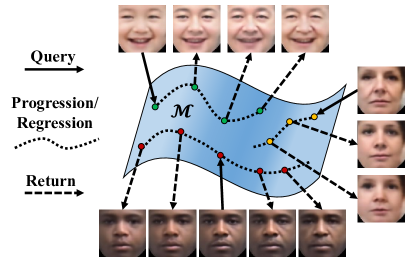
![Figure 2: Illustration of traversing on the face manifold $\mathcal{M}$ . The input faces $x_{1}$ and $x_{2}$ are encoded to $z_{1}$ and $z_{2}$ by an encoder $E$ , which represents the personality. Concatenated by random age labels $l_{1}$ and $l_{2}$ , the latent vectors $[z_{1},l_{1}]$ and $[z_{2](https://ar5iv.labs.arxiv.org/html/1702.08423/assets/x2.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.