[논문 리뷰] AI-assisted coding: Experiments with GPT-4
GPT-4는 실행 가능한 코드를 생성하고 리팩토링을 통해 가독성을 향상시킬 수 있지만, 테스트의 정확성과 신뢰성 측면에서 사람의 검증은 여전히 필수적이다. GPT-4가 생성한 테스트는 종종 실패하며 디버깅이 필요하다.
Artificial intelligence (AI) tools based on large language models have acheived human-level performance on some computer programming tasks. We report several experiments using GPT-4 to generate computer code. These experiments demonstrate that AI code generation using the current generation of tools, while powerful, requires substantial human validation to ensure accurate performance. We also demonstrate that GPT-4 refactoring of existing code can significantly improve that code along several established metrics for code quality, and we show that GPT-4 can generate tests with substantial coverage, but that many of the tests fail when applied to the associated code. These findings suggest that while AI coding tools are very powerful, they still require humans in the loop to ensure validity and accuracy of the results.
연구 동기 및 목표
- 최소한의 프롬프트 엔지니어링으로 인터랙티브한 데이터 과학 코딩 과제에서 GPT-4가 어떻게 수행되는지 평가한다.
- 기존 Python 코드의 리팩토링과 품질 향상 능력을 평가한다.
- 자신의 코드에 대한 테스트를 생성하고 그 테스트 커버리지를 평가하는 GPT-4의 능력을 조사한다.
- 과학 연구자를 위한 AI 코딩 도우미의 전반적 활용성 및 한계를 평가한다.
제안 방법
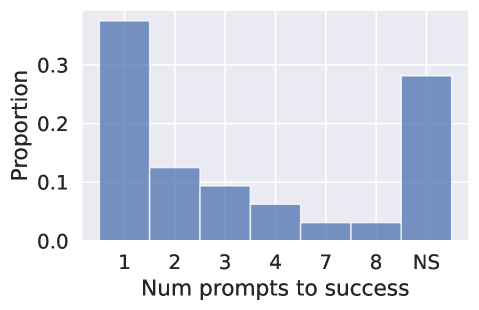
- 데이터 과학 문제에 대해 ChatGPT를 통한 GPT-4의 인터랙티브 코드 생성; 코드를 수정하고 완성하기 위한 여러 프롬프트 사용; 문제당 약 5분 내 성공 판단.
- GPT-4를 이용한 기존 Python 코드의 리팩토링, 품질과 관련성을 위해 GitHub의 274개 후보 파일 데이터세트 사용; 정적 분석 및 유지보수 지표로 코드 품질 평가.
- 자동 테스트 생성: GPT-4가 여러 도메인에 대한 코드와 테스트 생성을 위한 프롬프트를 만들고; run 가능한지 및 테스트 커버리지를 Coverage.py와 pytest로 평가하는 실행 스크립트 수행.
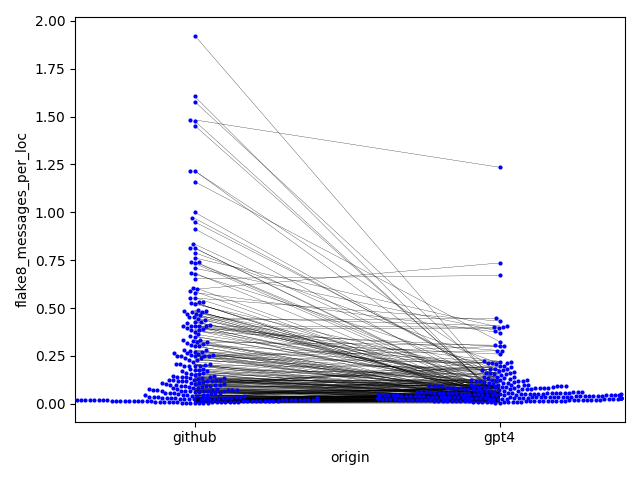
- 읽기 쉬움, 유지보수성, 복잡도, 스타일 등 지표에 대해 원본 코드와 리팩토링된 코드를 비교(flake8 및 radon 패키지 사용); FDR 보정이 적용된 대응표본 t-검정과 같은 통계 검정으로 차이 보고.
- 제한점 평가: 잘못된 출력이나 망상 출력 분석, 인간 검증의 필요성, 향후 연구로서 프롬 prompting 기법(예: chain-of-thought) 논의.
실험 결과
연구 질문
- RQ1최소한의 프롬프트 엔지니어링과 인간의 지도로도 GPT-4가 데이터 과학 문제에 대해 작동하는 Python 코드를 생성할 수 있는가?
- RQ2동작에 영향을 주지 않으면서 가독성과 유지보수성을 개선하기 위해 기존 코드를 리팩토링할 수 있는가?
- RQ3자신의 코드에 대해 충분한 커버리지의 테스트를 생성할 수 있으며, 이 테스트가 얼마나 자주 실패하거나 디버깅이 필요한가?
- RQ4연구자를 위한 AI 코딩 도우미로서 GPT-4의 전반적 활용성과 한계는 무엇인가?
주요 결과
| 지표 | GitHub 중앙값 | GPT-4 중앙값 | Cohen의 d | P-값 (FDR) |
|---|---|---|---|---|
| 유지보수 지수 | 70.285 | 74.092 | 0.33 | <.001 |
| Halstead 버그 수 | 0.081 | 0.068 | 0.13 | 0.045 |
| Halstead 난이도 | 3.214 | 3.089 | 0.16 | 0.012 |
| 라인당 flake8 메시지 | 0.237 | 0.089 | 0.50 | <.001 |
| 평균 사이클로매틱 복잡도 | 3.462 | 3.284 | 0.18 | 0.006 |
| 주석 수 | 7.81 | 7.086 | 0.08 | 0.196 |
| 논리적 코드 줄 수 | 46.022 | 43.372 | 0.27 | <.001 |
- 시도 중 72% (23/32)에서 GPT-4로 합성 코드 결과가 성공적이었고, 첫 프롬프트에서의 성공률은 37.5% (12/32)였다.
- 리팩토링된 코드는 줄당 flake8 메시지가 현저히 감소해(0.23 대 0.09) 표준 준수와 가독성 향상을 시사했다(Cohen’s d = 0.50).
- 리팩토링 후 유지보수 지수, Halstead 지표, Cyclomatic 복잡도가 평균적으로 개선되었고(작은-중간 효과 크기, p < .05 after FDR).
- GPT-4가 코드에 대한 테스트를 높은 커버리지를 생성했지만 통합 후 100개 중 45개 테스트만 통과했고, 다수의 테스트는 잘못된 가정이나 맥락 누락으로 실패했다.
- 대부분의 스크립트(97/100)가 실패 없이 실행되었으나 테스트와 코드 간의 불일치나 실패를 해결하기 위한 상당한 디버깅이 필요했다.
- 연구는 수학적 및 도메인 특화 측면에서의 정확성을 위해 인간 개입이 여전히 필수적임을 강조한다, GPT-4에도 불구하고.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.