[논문 리뷰] AlphaBlock: Embodied Finetuning for Vision-Language Reasoning in Robot Manipulation
AlphaBlock은 AlphaBlock 데이터셋과 CogLoop를 소개합니다. 이 프레임워크는 비전-언어 로봇 계획을 폐쇄 루프 방식으로 수행하며, 비전 어댑터와 Q-former를 갖춘 LLM을 사용해 조작 작업의 고수준 하위 과업(plan)들을 생성·갱신하고, 기존 방법보다 더 높은 성공률을 달성합니다.
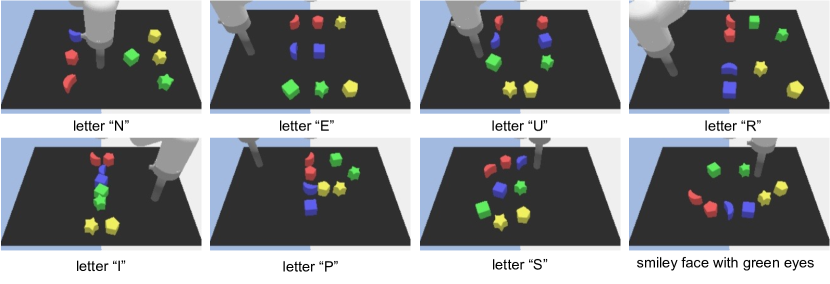
We propose a novel framework for learning high-level cognitive capabilities in robot manipulation tasks, such as making a smiley face using building blocks. These tasks often involve complex multi-step reasoning, presenting significant challenges due to the limited paired data connecting human instructions (e.g., making a smiley face) and robot actions (e.g., end-effector movement). Existing approaches relieve this challenge by adopting an open-loop paradigm decomposing high-level instructions into simple sub-task plans, and executing them step-by-step using low-level control models. However, these approaches are short of instant observations in multi-step reasoning, leading to sub-optimal results. To address this issue, we propose to automatically collect a cognitive robot dataset by Large Language Models (LLMs). The resulting dataset AlphaBlock consists of 35 comprehensive high-level tasks of multi-step text plans and paired observation sequences. To enable efficient data acquisition, we employ elaborated multi-round prompt designs that effectively reduce the burden of extensive human involvement. We further propose a closed-loop multi-modal embodied planning model that autoregressively generates plans by taking image observations as input. To facilitate effective learning, we leverage MiniGPT-4 with a frozen visual encoder and LLM, and finetune additional vision adapter and Q-former to enable fine-grained spatial perception for manipulation tasks. We conduct experiments to verify the superiority over existing open and closed-loop methods, and achieve a significant increase in success rate by 21.4% and 14.5% over ChatGPT and GPT-4 based robot tasks. Real-world demos are shown in https://www.youtube.com/watch?v=ayAzID1_qQk .
연구 동기 및 목표
- 언어 지시에 의해 안내되는 다단계 추론을 통해 로봇 조작에서의 고수준 인지 능력 학습을 촉진한다.
- LLMs와 실행 모델을 이용해 인지 로봇 데이터셋을 자동으로 생성함으로써 데이터 수집 부담을 줄인다.
- 시각 특징과 언어를 융합해 하위 작업(plan)을 생성하는 다중 모달 계획 모델을 개발한다.
- 동결된 LLM과 비전 인코더, 경량 어댑터를 활용한 로봇 작업의 엔드-투-엔드 학습을 가능하게 한다.
제안 방법
- 다단계 프롬프트로 GPT-4를 자극하여 고수준 작업, 하위 작업 계획, 관찰-행동 시퀀스를 생성하고 AlphaBlock 데이터셋을 수집하며; LAVA를 실행 모델로 사용해 실시간 계획 데이터를 생성한다.
- Vision Adapter와 Vision Tokenizer(Q-former + projector)를 사용해 미세한 공간 인식을 위한 ViT 기반 시각 특징을 고정된 언어 디코더(Vicuna via LLaMA)와 정렬하는 디코더 아키텍처 CogLoop를 제안한다.
- 필요에 따라 어댑터와 Q-former를 조정하고 LLM 및 비전 인코더를 고정한 채 교차 엔트로피 손실로 자기회귀 하위 작업 계획을 생성하도록 CogLoop를 훈련한다.
- 데이터 품질을 보장하고 데이터 수집 시 인간 노동을 줄이기 위해 역추적 형 프롬 prompting 및 자기 검증 전략을 활용한다.
- 시뮬레이션된 LAVA 기반 컨트롤러를 사용해 CogLoop를 개방 루프 및 폐쇄 루프 기준선과 비교 평가하고, 단계 수, 재계획 빈도 및 모달리티 구성 요소에 대한 소거 실험을 수행한다.
![Figure 1: Planner model paradigms. (a) Open-loop models (SayCan-style [ 16 ] ) conduct planning and control separately. (b) Closed-loop models update plans with observation in language (Text2Motion-style [ 24 ] ). (c) We infuse more fine-grained visual observation into LLM to update planning.](https://ar5iv.labs.arxiv.org/html/2305.18898/assets/x1.png)
실험 결과
연구 질문
- RQ1AlphaBlock 데이터가 기존의 개방 루프(open-loop) 및 폐쇄 루프(closed-loop) 방법을 넘어 로봇 조작에 대한 고수준 인지 계획을 개선할 수 있는가?
- RQ2실시간으로 하위 작업 계획을 업데이트하는 데 있어 언어만 관찰하는 방식보다 비전-언어 폐쇄 루프 계획 접근이 우수한가?
- RQ3비전 어댑터와 Q-former 기반 모달리티 정합이 로봇의 계획 성능과 공간 추론에 어떤 영향을 미치는가?
- RQ4로봇에서 효과적인 인지를 위한 계획/업데이트 주기와 계산 비용 간의 트레이드오프는 무엇인가?
주요 결과
| 예시 모델 유형 | 오픈/클로즈드 루프 | 재구현 계획 모델 | 성공률 (%) |
|---|---|---|---|
| SayCan [16] , open | ChatGPT | 8.1 | |
| Grounded Decoding [14] | GPT-4 | 9.0 | |
| Text2Motion [24] closed w/ language | ChatGPT | 2.1 | |
| ChatGPT for Robotics [38] | GPT-4 | 16.4 | |
| Ours (CogLoop) closed w/ vision | Embodied robot model | 23.5 |
- CogLoop with vision-based closed-loop planning achieves a 23.5% success rate, outperforming baselines including ChatGPT (16.4%) and GPT-4 with language observations.
- AlphaBlock enables significant improvements over ChatGPT (+21.4%) and GPT-4 (+7.1%) when using vision-informed plan updates.
- Vision adapters and tuning the Vision Q-former materially improve performance; the best results arise from tuning both components.
- Increasing total steps improves success rate up to convergence around 150 steps, and more frequent re-planning (every 10 steps) boosts success at the cost of time; re-planning every 10 steps is a practical balance.
- Real-world deployment on a Franka Emika arm with Kinect sensing demonstrates transfer from simulation to physical environments.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.