[논문 리뷰] ARB: Advanced Reasoning Benchmark for Large Language Models
ARB는 수학, 물리학, 화학, 생물학, 법에 걸친 고난도 대학원 수준의 추론 벤치마크입니다. 이 벤치마크는 루브릭 기반의 자가 평가 방식을 도입하고, 현재의 LLM들이 고급 정량적 작업에서 여전히 성능이 모자란다는 것을 보여줍니다.
Large Language Models (LLMs) have demonstrated remarkable performance on various quantitative reasoning and knowledge benchmarks. However, many of these benchmarks are losing utility as LLMs get increasingly high scores, despite not yet reaching expert performance in these domains. We introduce ARB, a novel benchmark composed of advanced reasoning problems in multiple fields. ARB presents a more challenging test than prior benchmarks, featuring problems in mathematics, physics, biology, chemistry, and law. As a subset of ARB, we introduce a challenging set of math and physics problems which require advanced symbolic reasoning and domain knowledge. We evaluate recent models such as GPT-4 and Claude on ARB and demonstrate that current models score well below 50% on more demanding tasks. In order to improve both automatic and assisted evaluation capabilities, we introduce a rubric-based evaluation approach, allowing GPT-4 to score its own intermediate reasoning steps. Further, we conduct a human evaluation of the symbolic subset of ARB, finding promising agreement between annotators and GPT-4 rubric evaluation scores.
연구 동기 및 목표
- 다양한 도메인에 걸쳐 전문가 수준의 대학원 수준 추론을 평가하기 위한 새로운 벤치마크로 ARB를 소개한다.
- 전문/대학원 자료에서 가져온 수학, 물리학, 생물학, 화학, 법 등 다양한 문제를 제공한다.
- 중간 추론 단계를 자가 평가할 수 있는 루브릭 기반 평가를 제안하고 검증한다.
- 모델 성능(GPT-4, GPT-3.5, Claude)을 시연하고 오답 유형 및 평가 신뢰성을 분석한다.
제안 방법
- 다중선택, 서술형, 서답형의 세 가지 문제 유형으로 구성된 벤치마크로, 서술형/개방형 문제의 비중이 더 높은 편이다.
- 문제의 난이도를 대학원 수준으로 보장하기 위해 표준화된 테스트, 문제집, 대학원 시험, 바(bar)/법학 자료에서 문제를 수집한다.
- 다중선택 및 수치형 답안에 대해 자동 파싱 및 채점 절차를 사용하고 기호적 답안은 SymPy 기반 파싱을 사용한다.
- 참고 해답으로부터 루브릭을 생성하고 이를 이용해 솔루션을 평가하는 모델 기반 루브릭 평가 방법을 도입한다.
- 루브릭 기반 점수와 비교하기 위해 기호적 부분에 대해 인간 평가를 수행하고 포괄성 및 채점 배분을 평가한다.
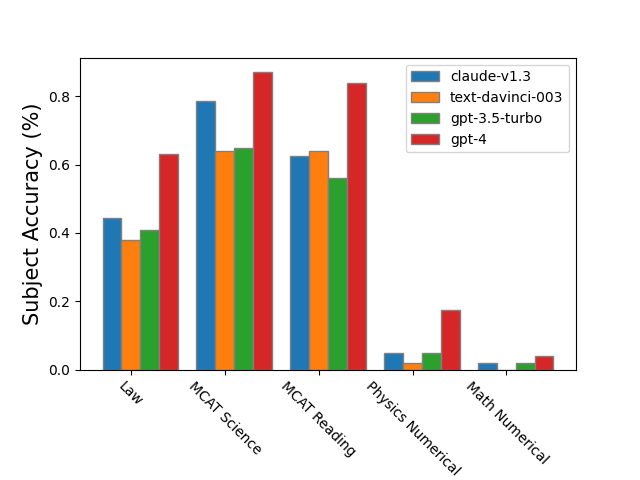
실험 결과
연구 질문
- RQ1다양한 도메인에서 ARB의 고급 추론 과제에 대해 현재의 LLM(GPT-4, GPT-3.5, Claude)은 어떤 성능을 보이는가?
- RQ2루브릭 생성 모델 기반 평가가 기호적 및 증명 유사 문제에 대해 인간 채점을 신뢰성 있게 근사할 수 있는가?
- RQ3고급 수학 및 물리 문제에서 LLM이 어떤 유형의 오류를 범하며, 문제 유형에 따라 이러한 오류가 어떻게 다른가?
- RQ4루브릭을 통한 자가 평가가 인간 판단과 상관관계를 가지며 자동 채점의 견고성을 향상시키는가?
주요 결과
- 현재 모델은 ARB의 많은 고난도 정량적 과제에서 전문가 수준보다 낮은 점수를 받는다.
- GPT-4는 복잡한 표현을 단순화할 수 있지만 여전히 긴 맥락의 산술 및 기호 조작에는 어려움을 겪는다.
- 기호적이고 증명 유사한 문제는 모델 간에 현저한 실패율을 보이며, 여러 범주에 대해 명시적 표 기반 백분율이 보고된다.
- GPT-4에 의한 루브릭 기반 평가가 인간 점수와 비교해 중등도 높은 상관관계를 보인다(예: 물리 기호, 수학 기호, 증명 유사 문제).
- GPT-4가 생성한 루브릭은 핵심 해답 단계를 잘 다루지만 점수 배분에 오차가 생길 수 있다; 루브릭 기반 점수화는 평가 노력을 줄이고 수기 채점과의 일치를 보인다.
- 모델 기반의 루브릭 평가 방법은 정확성의 자동화된 대리 척도로써 가능성이 있지만 인간 채점을 완전히 대체하지는 않는다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.