[논문 리뷰] Assessing the performance of spatial cross-validation approaches for models of spatially structured data
본 논문은 풍경 시뮬레이션을 통해 공간적으로 구조화된 데이터에 대한 공간 교차 검증(spatial cross-validation) 방법을 비교하고, 공간 OUT 블록과 버퍼를 포함한 공간 CV가 성능 추정치를 더 정확하게 만든다는 점을 확인하며, tidymodels 프레임워크 내에서 spatialsample R 패키지를 도입한다.
Evaluating models fit to data with internal spatial structure requires specific cross-validation (CV) approaches, because randomly selecting assessment data may produce assessment sets that are not truly independent of data used to train the model. Many spatial CV methodologies have been proposed to address this by forcing models to extrapolate spatially when predicting the assessment set. However, to date there exists little guidance on which methods yield the most accurate estimates of model performance. We conducted simulations to compare model performance estimates produced by five common CV methods fit to spatially structured data. We found spatial CV approaches generally improved upon resubstitution and V-fold CV estimates, particularly when approaches which combined assessment sets of spatially conjunct observations with spatial exclusion buffers. To facilitate use of these techniques, we introduce the `spatialsample` package which provides tooling for performing spatial CV as part of the broader tidymodels modeling framework.
연구 동기 및 목표
- 훈련 데이터의 공간 자기상관으로 인한 과도하게 낙관적인 성능을 피하기 위해 공간 교차 검증의 필요성을 제기한다.
- 시뮬레이션된 풍경과 랜덤 포레스트를 사용하여 주요 공간 CV 방법들을 체계적으로 비교한다.
- 정확한 모델 성능 추정치를 산출하는 파라미터 설정을 식별하고 실용적인 지침을 제공한다.
- tidymodels 생태계 내에서 공간 CV를 구현하는 접근 가능한 소프트웨어 도구를 제공한다.
제안 방법
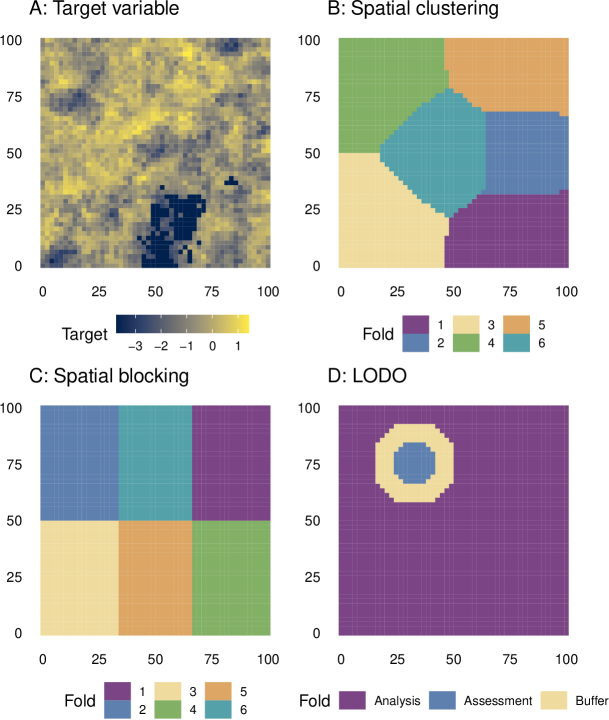
- 13개의 예측변수와 파생 타깃 변수 y를 가진 50x50 그리드에서 독립적인 100개의 시뮬레이션 풍경을 생성.
- 차단된 CV, 군집 CV, BLO3 CV, LODO CV, BLO3 CV, V-폴드 CV 등 여러 공간 CV 접근법을 재대입(resubstitution) 및 표준 무작위 CV와 비교했다.
- X2, X3, X6–X10 예측변수를 사용하여 y를 예측하는 랜덤 포레스트(ranger)를 적용했다.
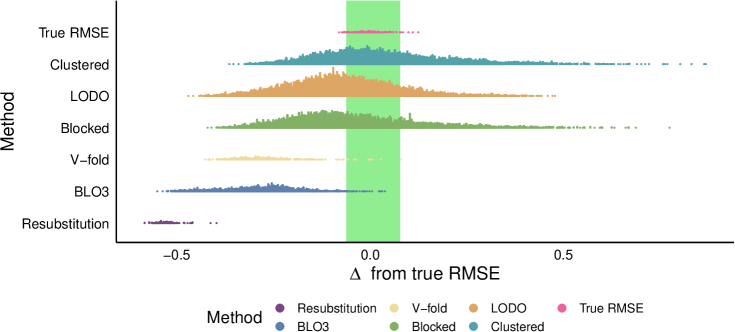
- RMSE로 모델 성능을 측정하고, 교차-풍경 예측으로부터 파생된 ‘진짜’ RMSE 범위와 추정치를 비교했다.
- y 및 잔차에 대한 공간 자기상관 범위를 계산하여 적절한 D_in/D_out 간격을 판단했다.
- 모든 방법을 spatialsample에서 구현하고 tidymodels 인프라에 맞추었다.
실험 결과
연구 질문
- RQ1공간적으로 구조화된 데이터의 모델 일반화를 추정하는 데 다양한 공간 교차 검증 접근법이 어떤 성능을 보이는가?
- RQ2공간적으로 연결된 평가 데이터와 배제 버퍼를 결합한 공간 CV 방법이 다른 접근법보다 더 정확한 성능 추정치를 제공하는가?
- RQ3어떤 매개변수 설정(블록 크기, 폴드 수, 버퍼, 포함 반경)이 진짜 RMSE 범위에 가장 근접한 RMSE 추정치를 산출하는가?
- RQ4D_in과 D_out 간격이 성능 추정치 편향에 어떤 영향을 미치는가?
- RQ5tidymodels 내의 실용적 도구가 이러한 공간 CV 방법을 적용 모델링 파이프라인에 효과적으로 구현할 수 있는가?
주요 결과
- 공간 CV 방법은 일반적으로 재대입(resubstitution) 또는 무작위 CV보다 더 정확한 성능 추정치를 제공한다.
- 공간적으로 연결된 관측치의 D_out를 배제 버퍼와 결합한 방법이 모델 성능의 가장 좋은 추정치를 제공했다.
- 공간 군집화 및 leave-one-disc-out (LODO) CV는 매개변수 설정 전반에 걸쳐 가장 일관되게 효과적인 접근법 중 하나였다.
- 데이터 배제가 지나치게 공격적일 때(예: 적은 수의 폴드나 지나치게 큰 블록) 비관적인 RMSE 추정치를 생성했다.
- 가장 성능이 좋은 매개변수 집합은 D_out를 D_in으로부터 그리드 길이의 대략 25–41%만큼 떨어뜨렸으며, 이는 결과의 자기상관 범위와 일치한다.
- Clustered CV는 매개변수 설정 전반에 걸쳐 강건성을 보였지만, 조사된 매개변수 공간이 더 좁을 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.