[논문 리뷰] Asynchronous Multi-Agent Reinforcement Learning for Efficient Real-Time Multi-Robot Cooperative Exploration
ACE는 비동기 설정으로 MAPPO를 확장하고 액션 지연 무작위화와 실시간 협동 탐험을 가능하게 하는 다중 타워 CNN 정책을 도입한다; 그 결과 그리드, 실제 세계, 그리고 Habitat 환경에서 계획 기반 및 동기 MARL 기준선을 능가한다.
We consider the problem of cooperative exploration where multiple robots need to cooperatively explore an unknown region as fast as possible. Multi-agent reinforcement learning (MARL) has recently become a trending paradigm for solving this challenge. However, existing MARL-based methods adopt action-making steps as the metric for exploration efficiency by assuming all the agents are acting in a fully synchronous manner: i.e., every single agent produces an action simultaneously and every single action is executed instantaneously at each time step. Despite its mathematical simplicity, such a synchronous MARL formulation can be problematic for real-world robotic applications. It can be typical that different robots may take slightly different wall-clock times to accomplish an atomic action or even periodically get lost due to hardware issues. Simply waiting for every robot being ready for the next action can be particularly time-inefficient. Therefore, we propose an asynchronous MARL solution, Asynchronous Coordination Explorer (ACE), to tackle this real-world challenge. We first extend a classical MARL algorithm, multi-agent PPO (MAPPO), to the asynchronous setting and additionally apply action-delay randomization to enforce the learned policy to generalize better to varying action delays in the real world. Moreover, each navigation agent is represented as a team-size-invariant CNN-based policy, which greatly benefits real-robot deployment by handling possible robot lost and allows bandwidth-efficient intra-agent communication through low-dimensional CNN features. We first validate our approach in a grid-based scenario. Both simulation and real-robot results show that ACE reduces over 10% actual exploration time compared with classical approaches. We also apply our framework to a high-fidelity visual-based environment, Habitat, achieving 28% improvement in exploration efficiency.
연구 동기 및 목표
- 비동기 액션 실행 하에서 다중 이기종 로봇의 실시간 협동 탐험 동기화.
- 액션 지연을 처리하고 탐험이 멈추지 않도록 오프라인 에이전트를 다루는 비동기 MARL 프레임워크 개발.
- 대 팀 규모에 따라 확장하고 대역폭을 최소화하는 효율적인 커뮤니케이션 정책 제안.
- 그리드 기반, 실제 세계 및 Habitat(비전 기반) 환경에서 우수한 탐험 효율성 시연.
제안 방법
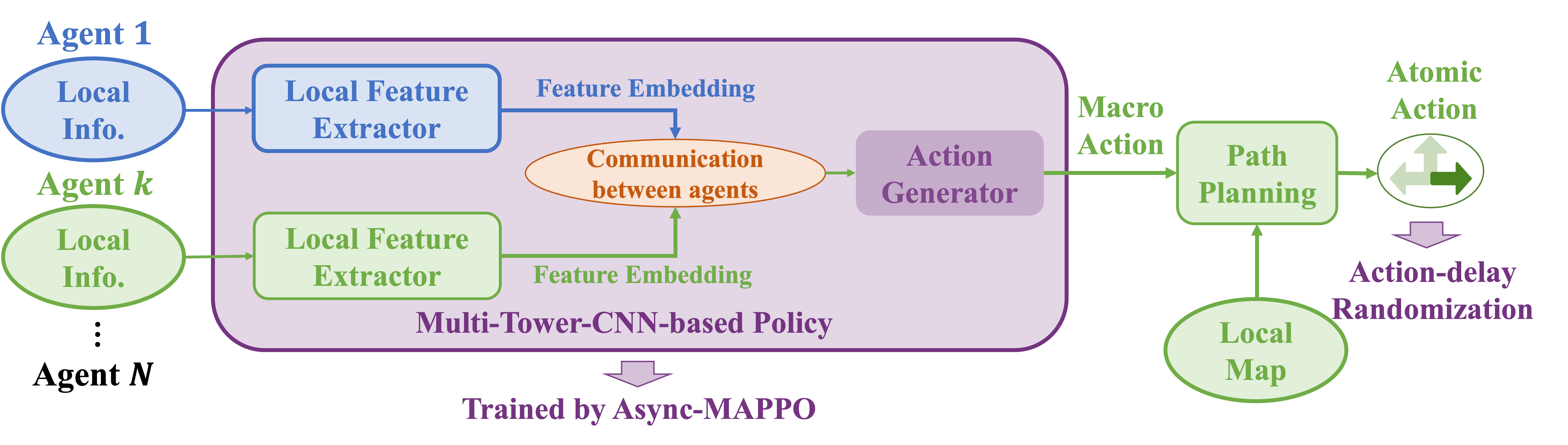
- MAPPO를 Async-MAPPO로 확장하여 비동기 액션 제작 지원 및 에이전트별 경험 버퍼 도입.
- 시뮬레이션 중 액션-지연 무작위를 도입해 varying delays에 대한 시뮬레이터-현실 일반화를 개선.
- 로컬 CNN 특징, 주의 기반 관계 인코더, 그리고 매크로 ACTION을 출력하는 디코더를 갖춘 다중-타워-CNN 기반 정책(MCP) 제안.
- 글로벌 목표와 원자 행동을 포함하는 Dec-POSMDP 형식을 도입하여 이중 수준 행동 실행 가능.
- 가중치 공유 정책과 제한된 특징 커뮤니케이션을 사용해 다양한 팀 규모를 처리하고 실제 적용의 견고성 확보.

실험 결과
연구 질문
- RQ1다중 로봇 협동 탐험을 위한 비동기 액션 실행에 MARL을 어떻게 적용할 수 있는가?
- RQ2액션-지연 무작위화가 시뮬레이터-현실 전이 및 실제 지연에 대한 견고성을 향상시키는가?
- RQ3CNN 기반의 크기 불변 정책이 제한된 대역폭으로 여러 로봇을 효과적으로 조정할 수 있는가?
- RQ4다른 환경에서 비동기 ACE와 계획 기반 및 동기 MARL 기준선 간 성능 향상은 어느 정도인가?
- RQ5ACE는 탐험 중 에이전트가 오프라인인 시나리오(N1에서 N2로)를 어떻게 다루며, 기준선에 비해 탐색 시간이 약 10% 더 빠르고 중복이 낮은가?
주요 결과
- ACE는 고전적 계획 기반 접근법과 비교하여 실제 탐험 시간을 10% 이상 단축한다.
- ACE는 Habitat(비전 기반 환경)에서 탐험 효율성을 28% 향상시킨다.
- 2대 로봇이 있는 실제 실험에서 ACE는 MAPPO 기저 대비 탐험 시간을 10.07% 단축한다.
- 실제 실험에서 가장 빠른 계획 기반 방법(Nearest) 대비 ACE의 탐험 시간은 33.86% 감소한다.
- ACE는 N1에서 N2로의 에이전트 손실 시나리오에 일반화해 대략 10% 더 빠른 탐험과 더 낮은 중복을 보이며 기준선에 비해 더 나은 성능을 보인다.
- ACE는 설정 전반에서 더 빠르게 완료하는 동안 누적 커버리지(ACS)를 유지하고 더 낮은 중복을 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.